
Information Science and Technology
Display Method:
2024,
54(4):
0401.
doi: 10.52396/JUSTC-2023-0091
Abstract:
Database watermarking is one of the most effective methods to protect the copyright of databases. However, traditional database watermarking has a potential drawback: watermark embedding will change the distribution of data, which may affect the use and analysis of databases. Considering that most analyses are based on the statistical characteristics of the target database, keeping the consistency of the statistical characteristics is the key to ensuring analyzability. Since statistical characteristics analysis is performed in groups, compared with traditional relational databases, time series databases (TSDBs) have obvious time-grouping characteristics and are more valuable for analysis. Therefore, this paper proposes a robust watermarking algorithm for time series databases, effectively ensuring the consistency of statistical characteristics. Based on the time-group characteristics of TSDBs, we propose a three-step watermarking method, which is based on linear regression, error compensation, and watermark verification, named RCV. According to the properties of the linear regression model and error compensation, the proposed watermark method generates a series of data that have the same statistical characteristics. Then, the verification mechanism is performed to validate the generated data until it conveys the target watermark message. Compared with the existing methods, our method achieves superior robustness and preserves constant statistical properties better.
Database watermarking is one of the most effective methods to protect the copyright of databases. However, traditional database watermarking has a potential drawback: watermark embedding will change the distribution of data, which may affect the use and analysis of databases. Considering that most analyses are based on the statistical characteristics of the target database, keeping the consistency of the statistical characteristics is the key to ensuring analyzability. Since statistical characteristics analysis is performed in groups, compared with traditional relational databases, time series databases (TSDBs) have obvious time-grouping characteristics and are more valuable for analysis. Therefore, this paper proposes a robust watermarking algorithm for time series databases, effectively ensuring the consistency of statistical characteristics. Based on the time-group characteristics of TSDBs, we propose a three-step watermarking method, which is based on linear regression, error compensation, and watermark verification, named RCV. According to the properties of the linear regression model and error compensation, the proposed watermark method generates a series of data that have the same statistical characteristics. Then, the verification mechanism is performed to validate the generated data until it conveys the target watermark message. Compared with the existing methods, our method achieves superior robustness and preserves constant statistical properties better.



2024,
54(4):
0402.
doi: 10.52396/JUSTC-2023-0061
Abstract:
Monocular depth estimation methods have achieved excellent robustness on diverse scenes, usually by predicting affine-invariant depth, up to an unknown scale and shift, rather than metric depth in that it is much easier to collect large-scale affine-invariant depth training data. However, in some video-based scenarios such as video depth estimation and 3D scene reconstruction, the unknown scale and shift residing in per-frame prediction may cause the predicted depth to be inconsistent. To tackle this problem, we propose a locally weighted linear regression method to recover the scale and shift map with very sparse anchor points, which ensures the consistency along consecutive frames. Extensive experiments show that our method can drop the Rel error (relative error) of existing state-of-the-art approaches significantly over several zero-shot benchmarks. Besides, we merge 6.3 million RGBD images to train robust depth models. By locally recovering scale and shift, our produced ResNet50-backbone model even outperforms the state-of-the-art DPT ViT-Large model. Combined with geometry-based reconstruction methods, we formulate a new dense 3D scene reconstruction pipeline, which benefits from both the scale consistency of sparse points and the robustness of monocular methods. By performing simple per-frame prediction over a video, the accurate 3D scene geometry can be recovered.
Monocular depth estimation methods have achieved excellent robustness on diverse scenes, usually by predicting affine-invariant depth, up to an unknown scale and shift, rather than metric depth in that it is much easier to collect large-scale affine-invariant depth training data. However, in some video-based scenarios such as video depth estimation and 3D scene reconstruction, the unknown scale and shift residing in per-frame prediction may cause the predicted depth to be inconsistent. To tackle this problem, we propose a locally weighted linear regression method to recover the scale and shift map with very sparse anchor points, which ensures the consistency along consecutive frames. Extensive experiments show that our method can drop the Rel error (relative error) of existing state-of-the-art approaches significantly over several zero-shot benchmarks. Besides, we merge 6.3 million RGBD images to train robust depth models. By locally recovering scale and shift, our produced ResNet50-backbone model even outperforms the state-of-the-art DPT ViT-Large model. Combined with geometry-based reconstruction methods, we formulate a new dense 3D scene reconstruction pipeline, which benefits from both the scale consistency of sparse points and the robustness of monocular methods. By performing simple per-frame prediction over a video, the accurate 3D scene geometry can be recovered.


2024,
54(4):
0403.
doi: 10.52396/JUSTC-2022-0174
Abstract:
The physics-informed neural network (PINN) is an emerging approach for efficiently solving partial differential equations (PDEs) using neural networks. The physics-informed convolutional neural network (PICNN), a variant of PINN enhanced by convolutional neural networks (CNNs), has achieved better results on a series of PDEs since the parameter-sharing property of CNNs is effective in learning spatial dependencies. However, applying existing PICNN-based methods to solve Navier–Stokes equations can generate oscillating predictions, which are inconsistent with the laws of physics and the conservation properties. To address this issue, we propose a novel method that combines PICNN with the finite volume method to obtain physically plausible and conservative solutions to Navier–Stokes equations. We derive the second-order upwind difference scheme of Navier–Stokes equations using the finite volume method. Then we use the derived scheme to calculate the partial derivatives and construct the physics-informed loss function. The proposed method is assessed by experiments on steady-state Navier–Stokes equations under different scenarios, including convective heat transfer and lid-driven cavity flow. The experimental results demonstrate that our method can effectively improve the plausibility and accuracy of the predicted solutions from PICNN.
The physics-informed neural network (PINN) is an emerging approach for efficiently solving partial differential equations (PDEs) using neural networks. The physics-informed convolutional neural network (PICNN), a variant of PINN enhanced by convolutional neural networks (CNNs), has achieved better results on a series of PDEs since the parameter-sharing property of CNNs is effective in learning spatial dependencies. However, applying existing PICNN-based methods to solve Navier–Stokes equations can generate oscillating predictions, which are inconsistent with the laws of physics and the conservation properties. To address this issue, we propose a novel method that combines PICNN with the finite volume method to obtain physically plausible and conservative solutions to Navier–Stokes equations. We derive the second-order upwind difference scheme of Navier–Stokes equations using the finite volume method. Then we use the derived scheme to calculate the partial derivatives and construct the physics-informed loss function. The proposed method is assessed by experiments on steady-state Navier–Stokes equations under different scenarios, including convective heat transfer and lid-driven cavity flow. The experimental results demonstrate that our method can effectively improve the plausibility and accuracy of the predicted solutions from PICNN.








2024,
54(4):
0404.
doi: 10.52396/JUSTC-2023-0010
Abstract:
When domains, which represent underlying data distributions, differ between training and test datasets, traditional deep neural networks suffer from a substantial drop in their performance. Domain generalization methods aim to boost generalizability on an unseen target domain by using only training data from source domains. Mainstream domain generalization algorithms usually make modifications on some popular feature extraction networks such as ResNet, or add more complex parameter modules after the feature extraction networks. Popular feature extraction networks are usually well pre-trained on large-scale datasets, so they have strong feature extraction abilities, while modifications can weaken such abilities. Adding more complex parameter modules results in a deeper network and is much more computationally demanding. In this paper, we propose a novel feature transfer model based on popular feature extraction networks in domain generalization, without making any changes or adding any module. The generalizability of this feature transfer model is boosted by incorporating a contrastive loss and a data augmentation strategy (i.e., Mixup), and a new sample selection strategy is proposed to coordinate Mixup and contrastive loss. Experiments on the benchmarks PACS and Domainnet demonstrate the superiority of our proposed method against conventional domain generalization methods.
When domains, which represent underlying data distributions, differ between training and test datasets, traditional deep neural networks suffer from a substantial drop in their performance. Domain generalization methods aim to boost generalizability on an unseen target domain by using only training data from source domains. Mainstream domain generalization algorithms usually make modifications on some popular feature extraction networks such as ResNet, or add more complex parameter modules after the feature extraction networks. Popular feature extraction networks are usually well pre-trained on large-scale datasets, so they have strong feature extraction abilities, while modifications can weaken such abilities. Adding more complex parameter modules results in a deeper network and is much more computationally demanding. In this paper, we propose a novel feature transfer model based on popular feature extraction networks in domain generalization, without making any changes or adding any module. The generalizability of this feature transfer model is boosted by incorporating a contrastive loss and a data augmentation strategy (i.e., Mixup), and a new sample selection strategy is proposed to coordinate Mixup and contrastive loss. Experiments on the benchmarks PACS and Domainnet demonstrate the superiority of our proposed method against conventional domain generalization methods.


2024,
54(4):
0405.
doi: 10.52396/JUSTC-2022-0100
Abstract:
In recommendation systems, bias is ubiquitous because the data are collected from user behaviors rather than from reasonable experiments. AutoDebias, which resorts to metalearning to find appropriate debiasing configurations, i.e., pseudolabels and confidence weights for all user-item pairs, has been demonstrated to be a generic and effective solution for tackling various biases. Nevertheless, setting pseudolabels and weights for every user-item pair can be a time-consuming process. Therefore, AutoDebias suffers from an enormous computational cost, making it less applicable to real cases. Although stochastic gradient descent with a uniform sampler can be applied to accelerate training, this approach significantly deteriorates model convergence and stability. To overcome this problem, we propose LightAutoDebias (short as LightAD), which equips AutoDebias with a specialized importance sampling strategy. The sampler can adaptively and dynamically draw informative training instances, which results in better convergence and stability than does the standard uniform sampler. Several experiments on three benchmark datasets validate that our LightAD accelerates AutoDebias by several magnitudes while maintaining almost equal accuracy.
In recommendation systems, bias is ubiquitous because the data are collected from user behaviors rather than from reasonable experiments. AutoDebias, which resorts to metalearning to find appropriate debiasing configurations, i.e., pseudolabels and confidence weights for all user-item pairs, has been demonstrated to be a generic and effective solution for tackling various biases. Nevertheless, setting pseudolabels and weights for every user-item pair can be a time-consuming process. Therefore, AutoDebias suffers from an enormous computational cost, making it less applicable to real cases. Although stochastic gradient descent with a uniform sampler can be applied to accelerate training, this approach significantly deteriorates model convergence and stability. To overcome this problem, we propose LightAutoDebias (short as LightAD), which equips AutoDebias with a specialized importance sampling strategy. The sampler can adaptively and dynamically draw informative training instances, which results in better convergence and stability than does the standard uniform sampler. Several experiments on three benchmark datasets validate that our LightAD accelerates AutoDebias by several magnitudes while maintaining almost equal accuracy.


2024,
54(1):
0101.
doi: 10.52396/JUSTC-2023-0006
Abstract:
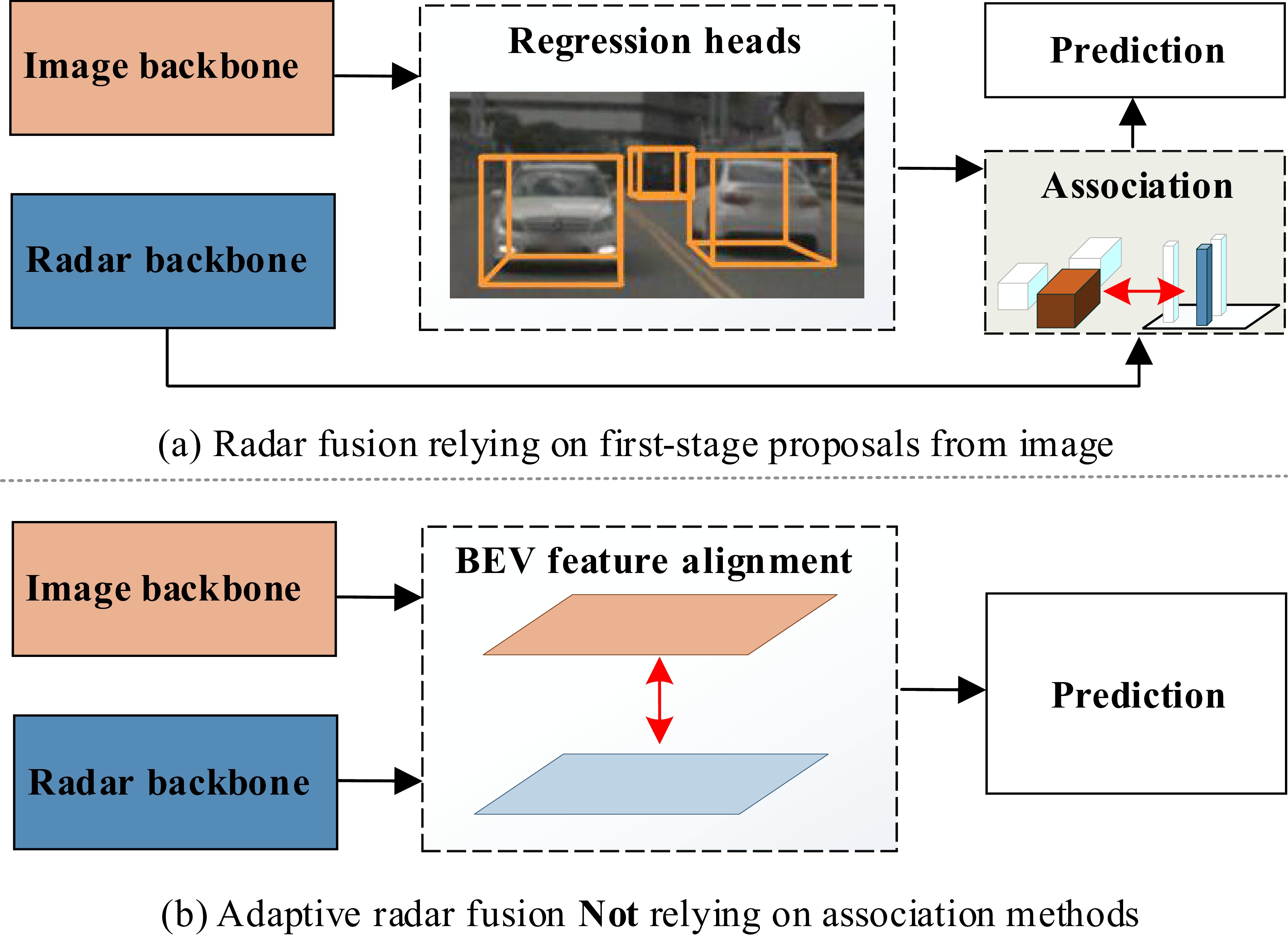
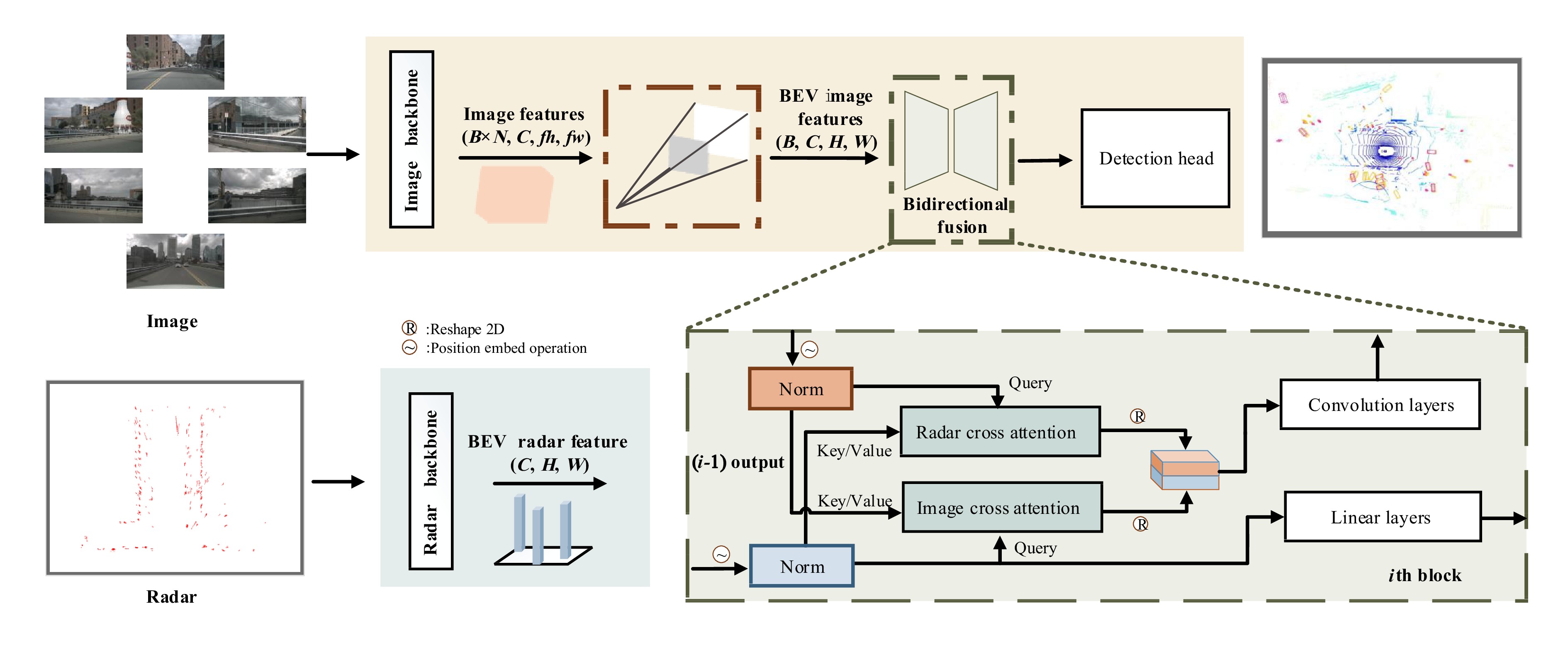
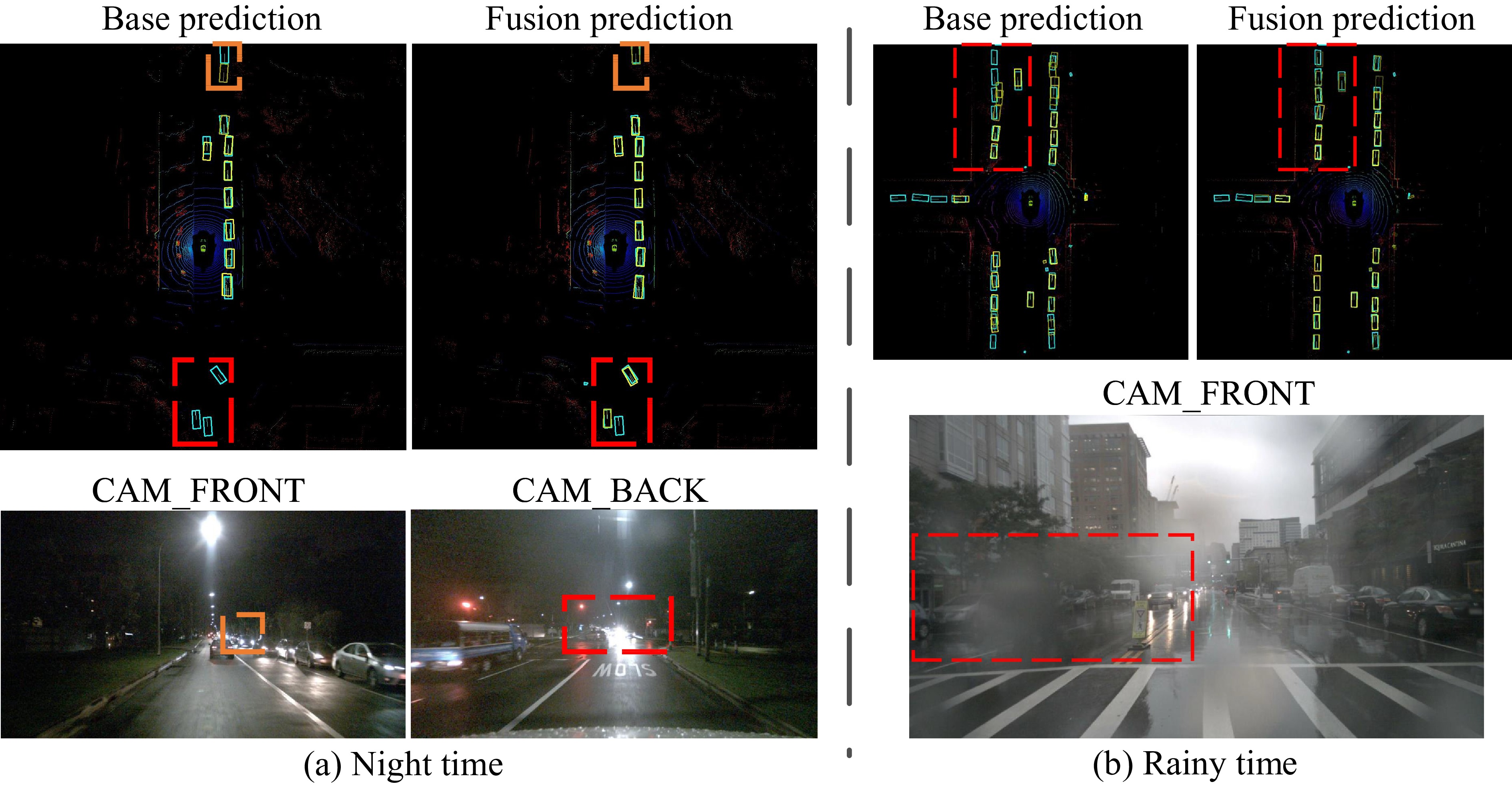
Exploring millimeter wave radar data as complementary to RGB images for ameliorating 3D object detection has become an emerging trend for autonomous driving systems. However, existing radar-camera fusion methods are highly dependent on the prior camera detection results, rendering the overall performance unsatisfactory. In this paper, we propose a bidirectional fusion scheme in the bird-eye view (BEV-radar), which is independent of prior camera detection results. Leveraging features from both modalities, our method designs a bidirectional attention-based fusion strategy. Specifically, following BEV-based 3D detection methods, our method engages a bidirectional transformer to embed information from both modalities and enforces the local spatial relationship according to subsequent convolution blocks. After embedding the features, the BEV features are decoded in the 3D object prediction head. We evaluate our method on the nuScenes dataset, achieving 48.2 mAP and 57.6 NDS. The result shows considerable improvements compared to the camera-only baseline, especially in terms of velocity prediction. The code is available athttps://github.com/Etah0409/BEV-Radar .
Exploring millimeter wave radar data as complementary to RGB images for ameliorating 3D object detection has become an emerging trend for autonomous driving systems. However, existing radar-camera fusion methods are highly dependent on the prior camera detection results, rendering the overall performance unsatisfactory. In this paper, we propose a bidirectional fusion scheme in the bird-eye view (BEV-radar), which is independent of prior camera detection results. Leveraging features from both modalities, our method designs a bidirectional attention-based fusion strategy. Specifically, following BEV-based 3D detection methods, our method engages a bidirectional transformer to embed information from both modalities and enforces the local spatial relationship according to subsequent convolution blocks. After embedding the features, the BEV features are decoded in the 3D object prediction head. We evaluate our method on the nuScenes dataset, achieving 48.2 mAP and 57.6 NDS. The result shows considerable improvements compared to the camera-only baseline, especially in terms of velocity prediction. The code is available at

2024,
54(1):
0102.
doi: 10.52396/JUSTC-2023-0002
Abstract:
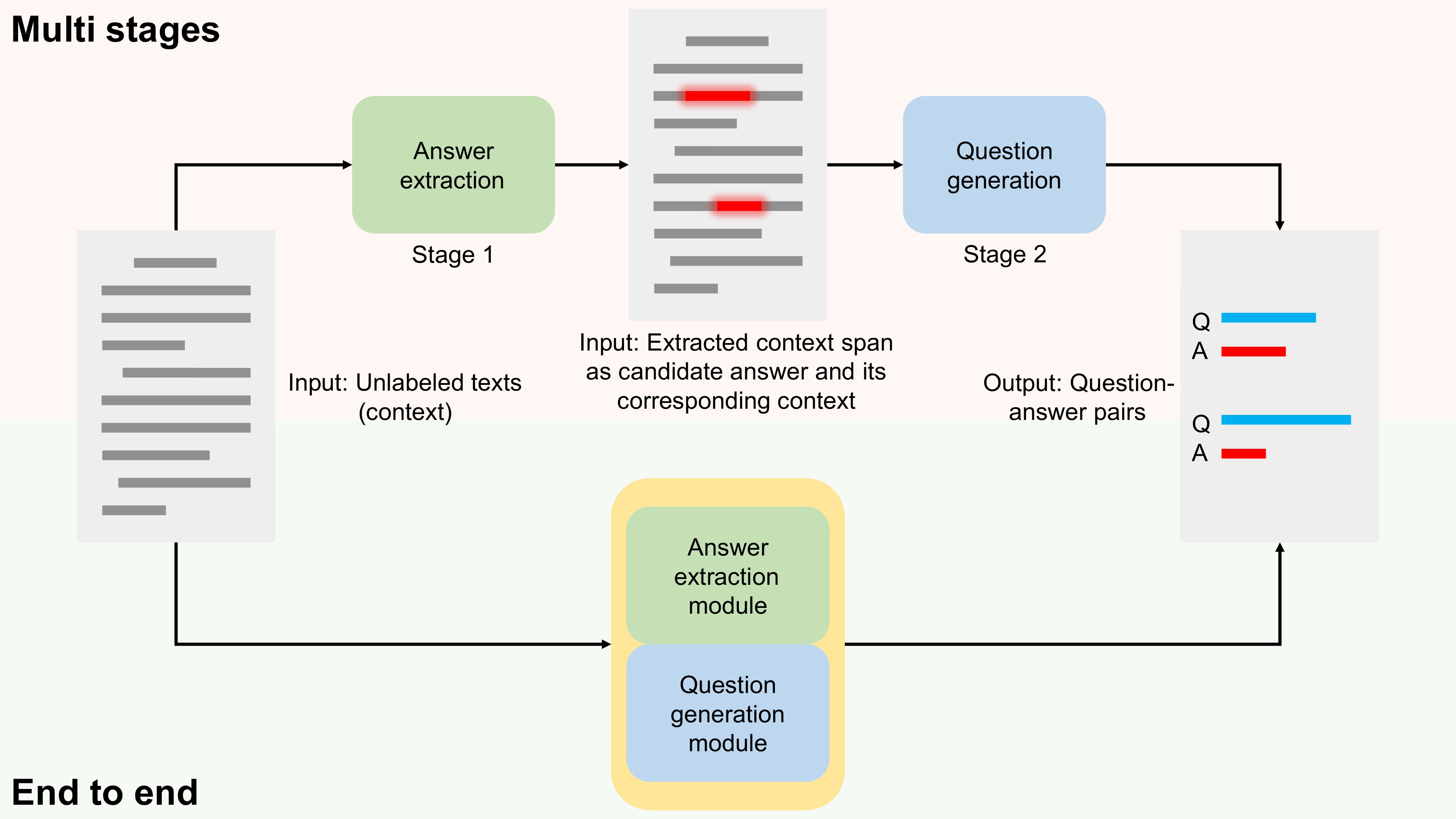
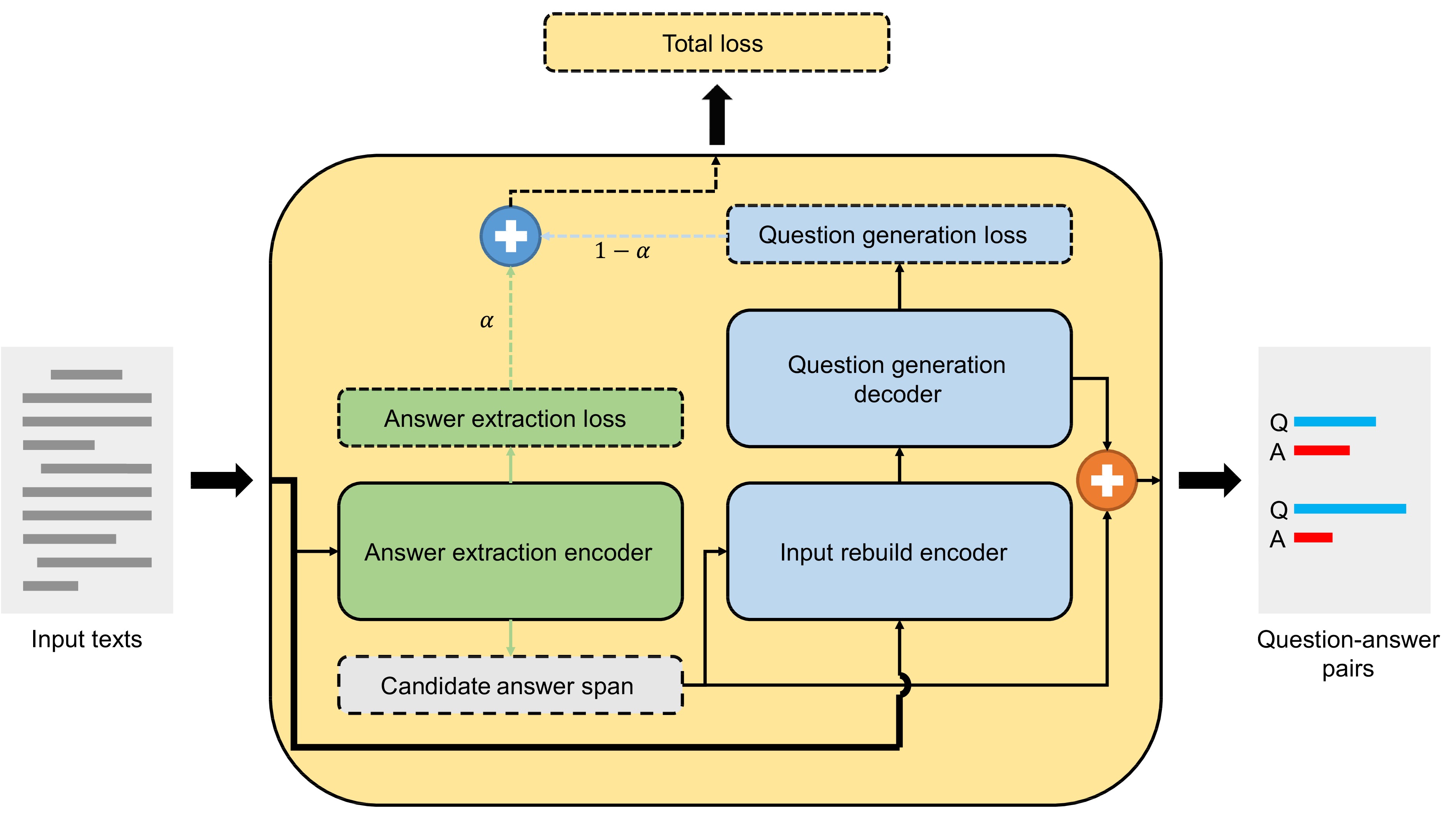
Question generation aims to generate meaningful and fluent questions, which can address the lack of a question-answer type annotated corpus by augmenting the available data. Using unannotated text with optional answers as input contents, question generation can be divided into two types based on whether answers are provided: answer-aware and answer-agnostic. While generating questions by providing answers is challenging, generating high-quality questions without providing answers is even more difficult for both humans and machines. To address this issue, we proposed a novel end-to-end model called question generation with answer extractor (QGAE), which is able to transform answer-agnostic question generation into answer-aware question generation by directly extracting candidate answers. This approach effectively utilizes unlabeled data for generating high-quality question-answer pairs, and its end-to-end design makes it more convenient than a multi-stage method that requires at least two pre-trained models. Moreover, our model achieves better average scores and greater diversity. Our experiments show that QGAE achieves significant improvements in generating question-answer pairs, making it a promising approach for question generation.
Question generation aims to generate meaningful and fluent questions, which can address the lack of a question-answer type annotated corpus by augmenting the available data. Using unannotated text with optional answers as input contents, question generation can be divided into two types based on whether answers are provided: answer-aware and answer-agnostic. While generating questions by providing answers is challenging, generating high-quality questions without providing answers is even more difficult for both humans and machines. To address this issue, we proposed a novel end-to-end model called question generation with answer extractor (QGAE), which is able to transform answer-agnostic question generation into answer-aware question generation by directly extracting candidate answers. This approach effectively utilizes unlabeled data for generating high-quality question-answer pairs, and its end-to-end design makes it more convenient than a multi-stage method that requires at least two pre-trained models. Moreover, our model achieves better average scores and greater diversity. Our experiments show that QGAE achieves significant improvements in generating question-answer pairs, making it a promising approach for question generation.
2024,
54(1):
0103.
doi: 10.52396/JUSTC-2022-0165
Abstract:
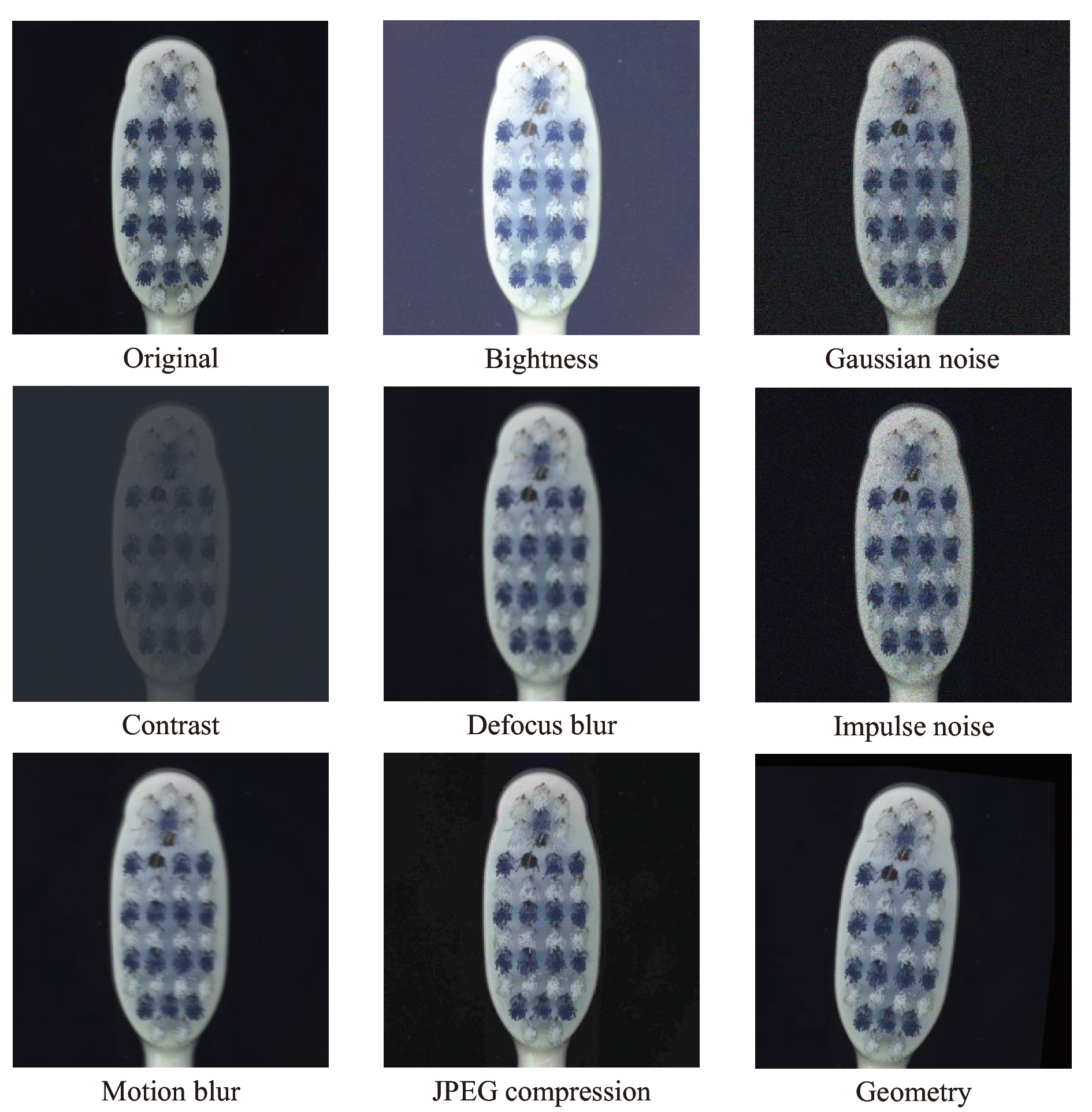
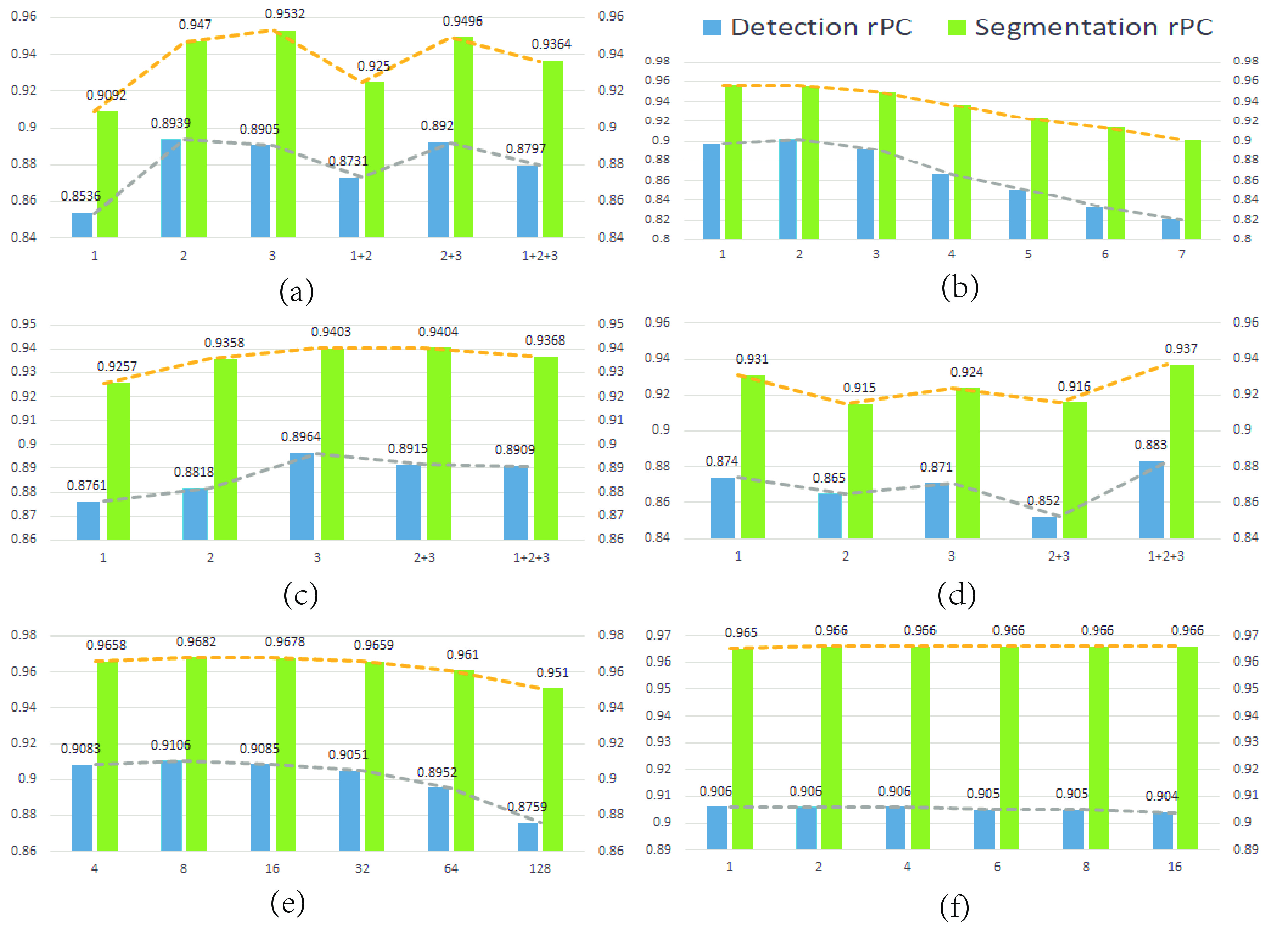
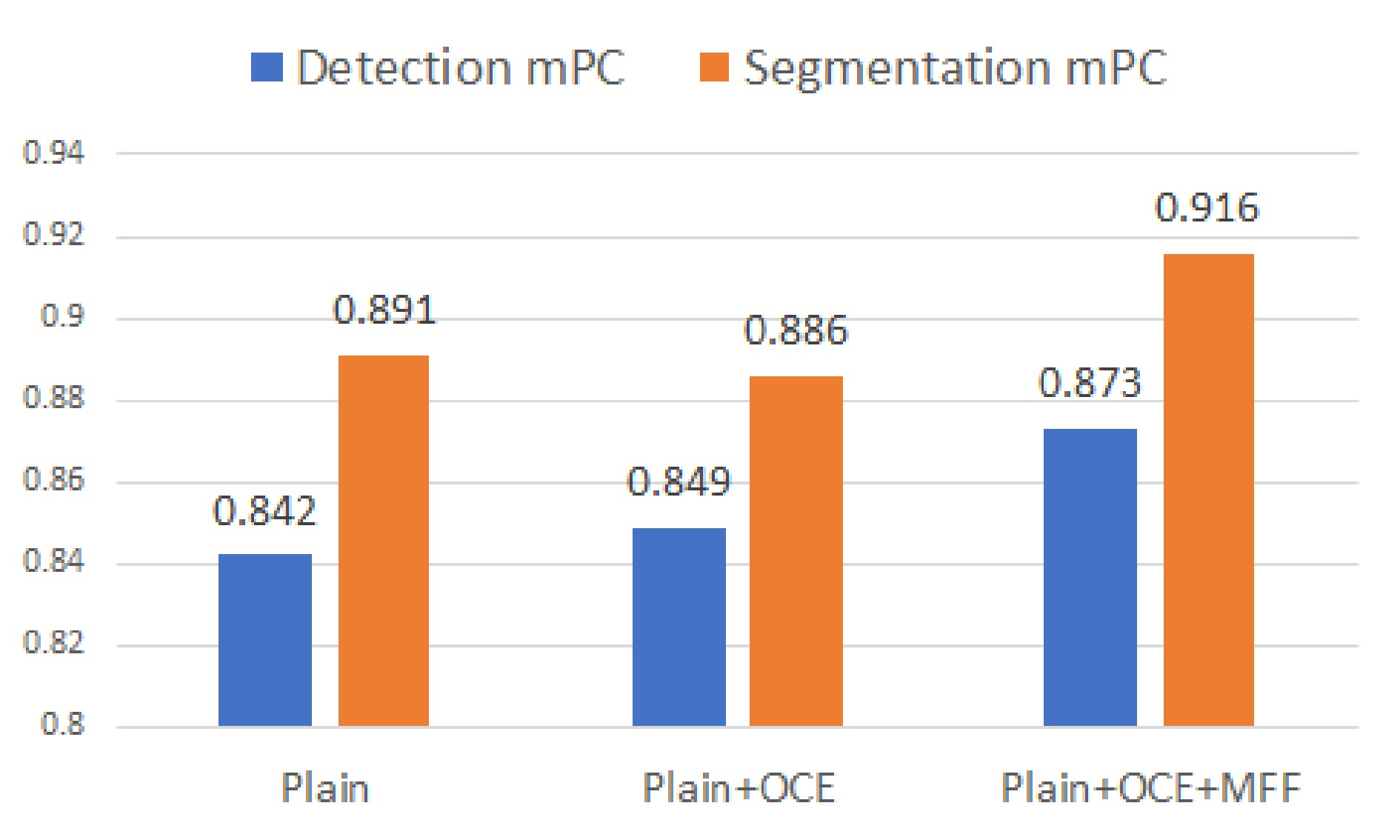
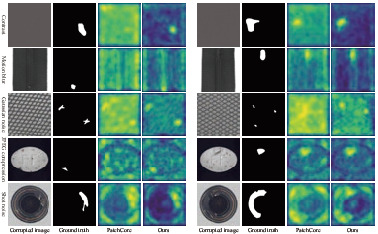
Due to the complexity and diversity of production environments, it is essential to understand the robustness of unsupervised anomaly detection models to common corruptions. To explore this issue systematically, we propose a dataset named MVTec-C to evaluate the robustness of unsupervised anomaly detection models. Based on this dataset, we explore the robustness of approaches in five paradigms, namely, reconstruction-based, representation similarity-based, normalizing flow-based, self-supervised representation learning-based, and knowledge distillation-based paradigms. Furthermore, we explore the impact of different modules within two optimal methods on robustness and accuracy. This includes the multi-scale features, the neighborhood size, and the sampling ratio in the PatchCore method, as well as the multi-scale features, the MMF module, the OCE module, and the multi-scale distillation in the Reverse Distillation method. Finally, we propose a feature alignment module (FAM) to reduce the feature drift caused by corruptions and combine PatchCore and the FAM to obtain a model with both high performance and high accuracy. We hope this work will serve as an evaluation method and provide experience in building robust anomaly detection models in the future.
Due to the complexity and diversity of production environments, it is essential to understand the robustness of unsupervised anomaly detection models to common corruptions. To explore this issue systematically, we propose a dataset named MVTec-C to evaluate the robustness of unsupervised anomaly detection models. Based on this dataset, we explore the robustness of approaches in five paradigms, namely, reconstruction-based, representation similarity-based, normalizing flow-based, self-supervised representation learning-based, and knowledge distillation-based paradigms. Furthermore, we explore the impact of different modules within two optimal methods on robustness and accuracy. This includes the multi-scale features, the neighborhood size, and the sampling ratio in the PatchCore method, as well as the multi-scale features, the MMF module, the OCE module, and the multi-scale distillation in the Reverse Distillation method. Finally, we propose a feature alignment module (FAM) to reduce the feature drift caused by corruptions and combine PatchCore and the FAM to obtain a model with both high performance and high accuracy. We hope this work will serve as an evaluation method and provide experience in building robust anomaly detection models in the future.

2024,
54(1):
0104.
doi: 10.52396/JUSTC-2022-0116
Abstract:
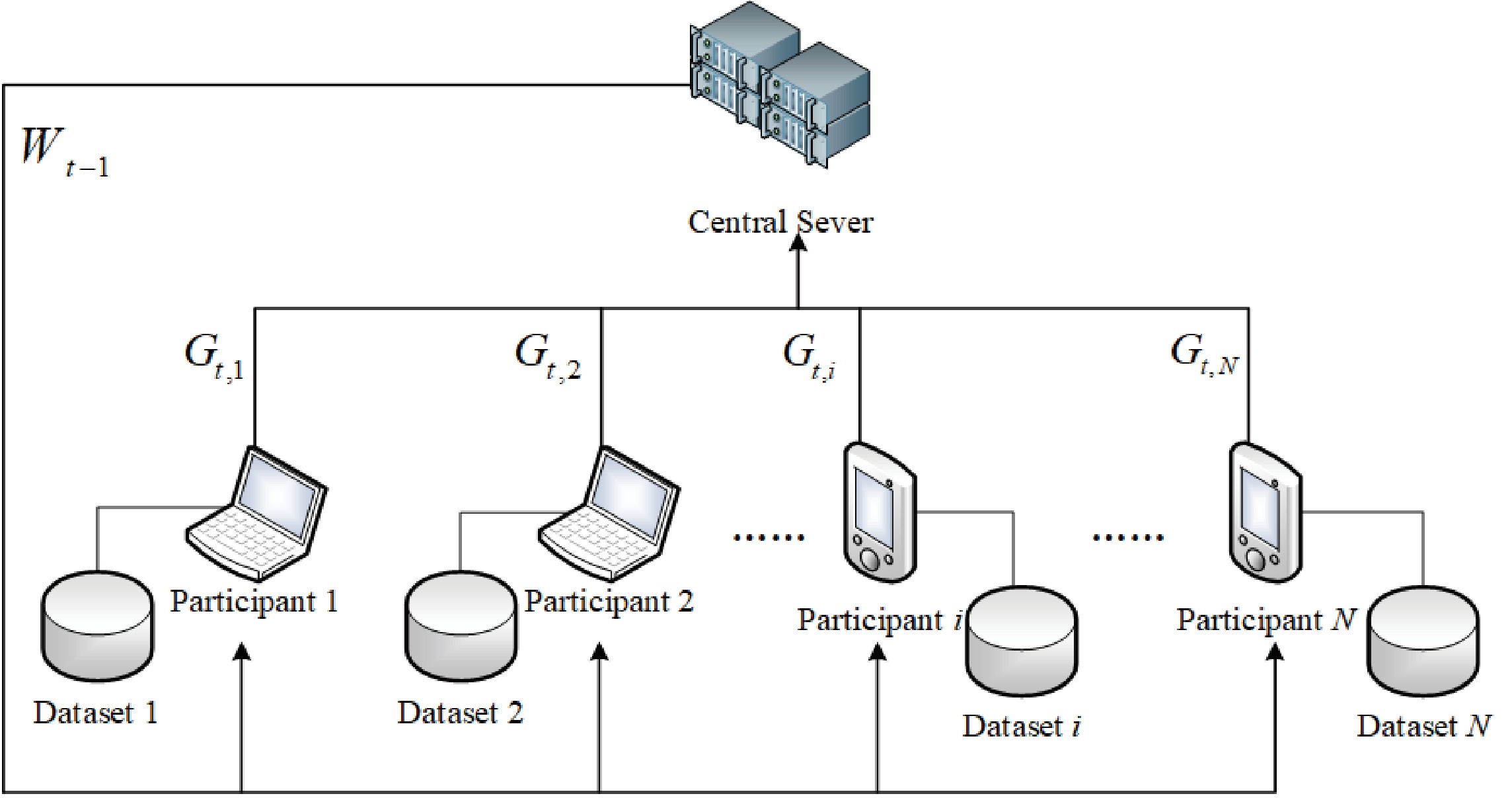
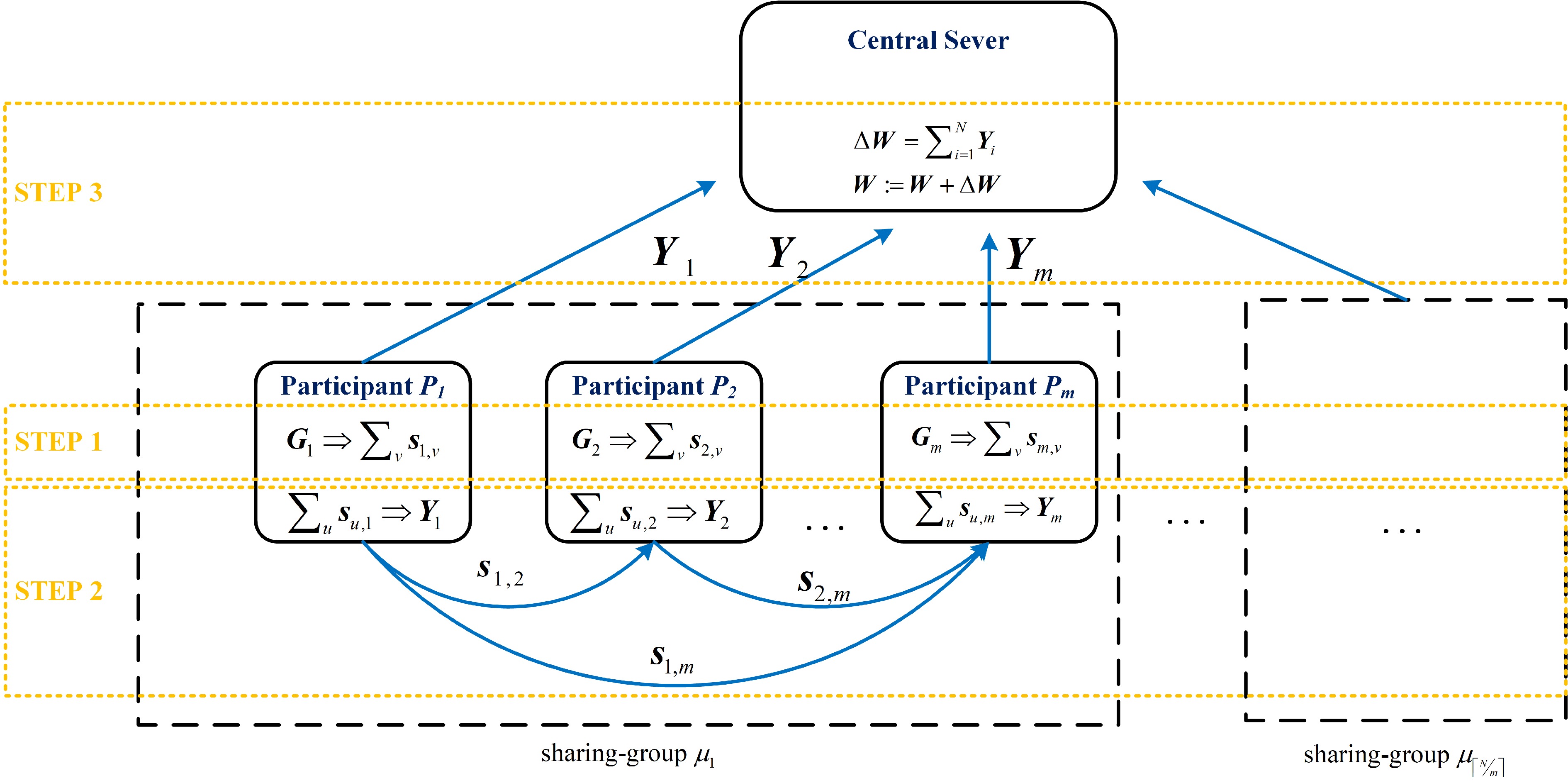
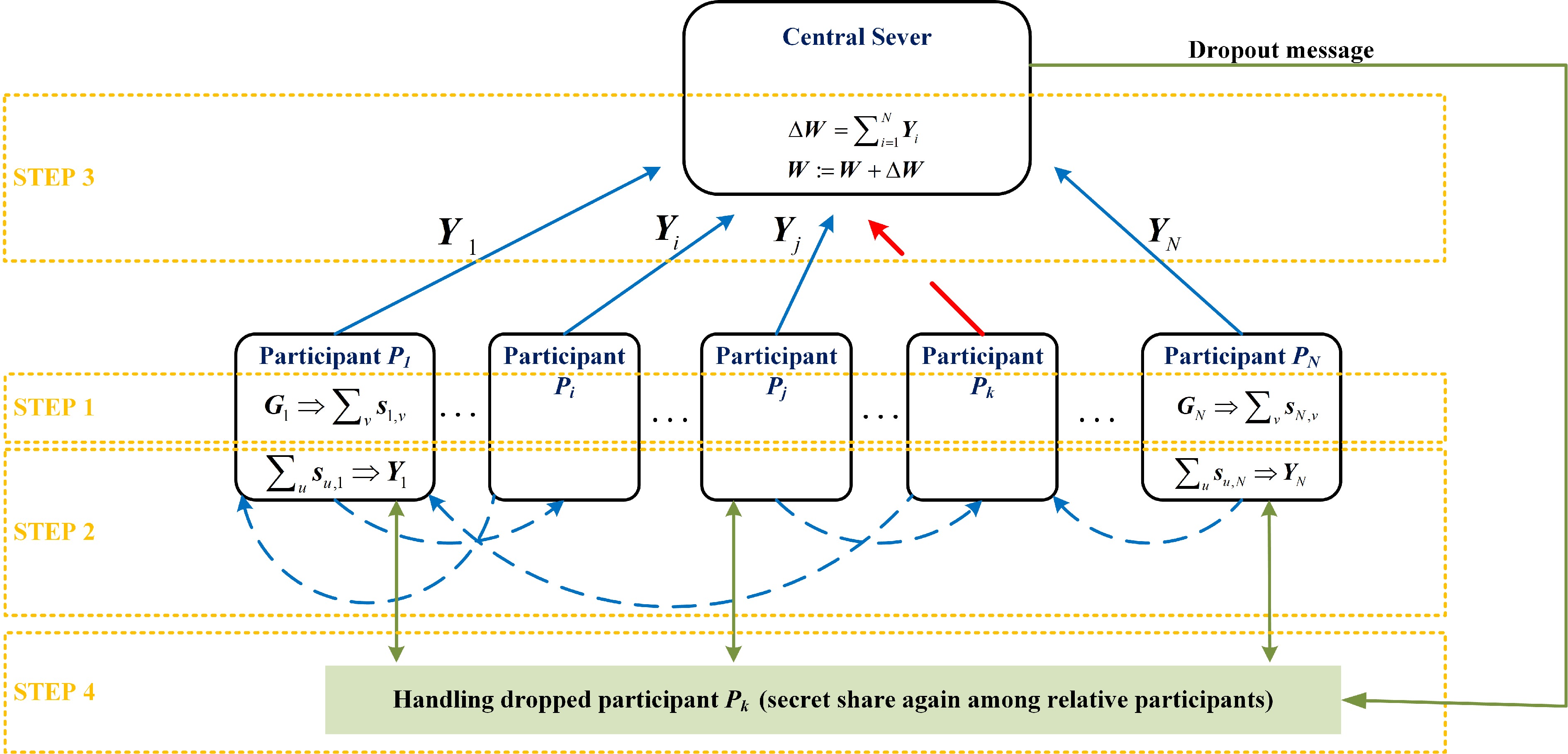
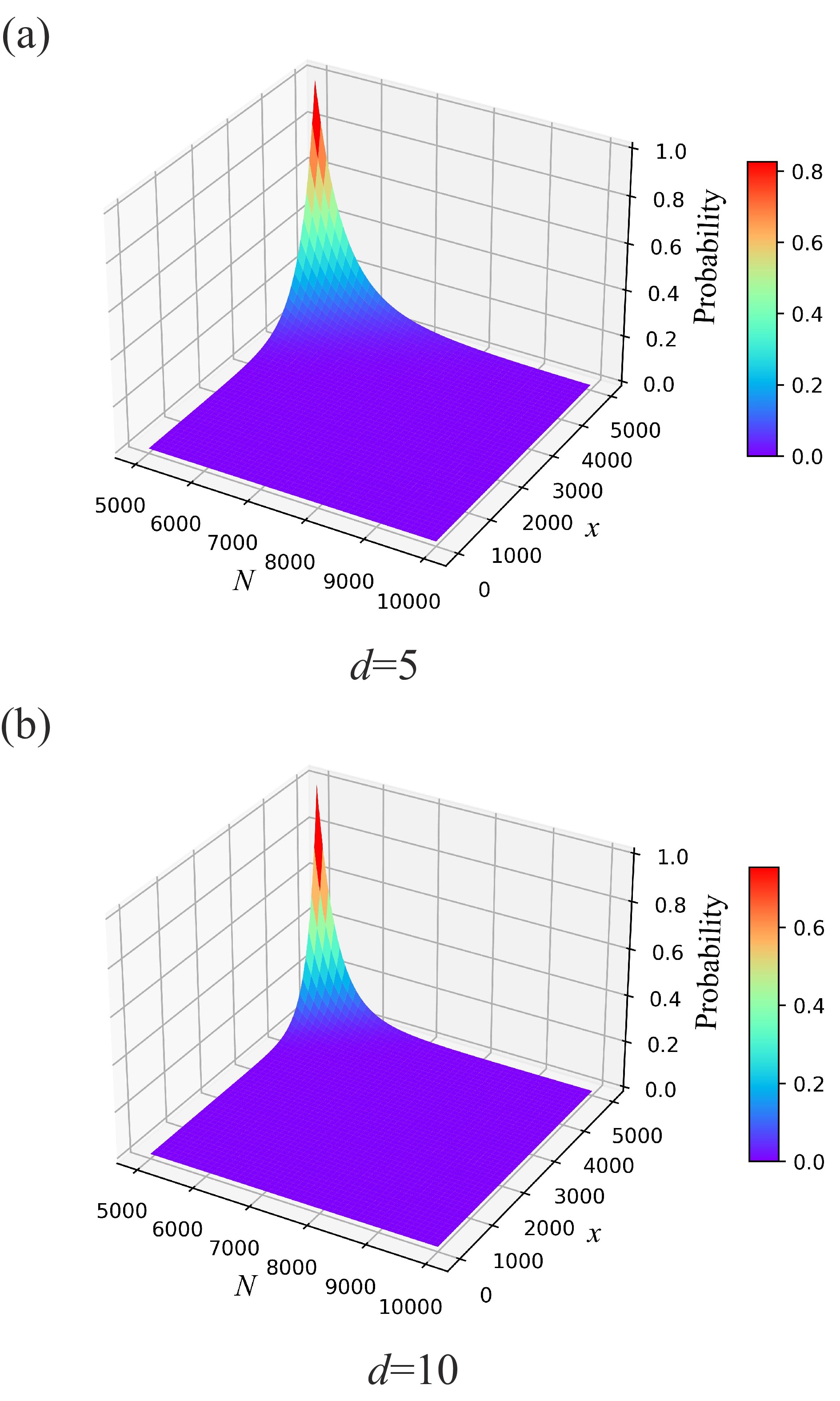
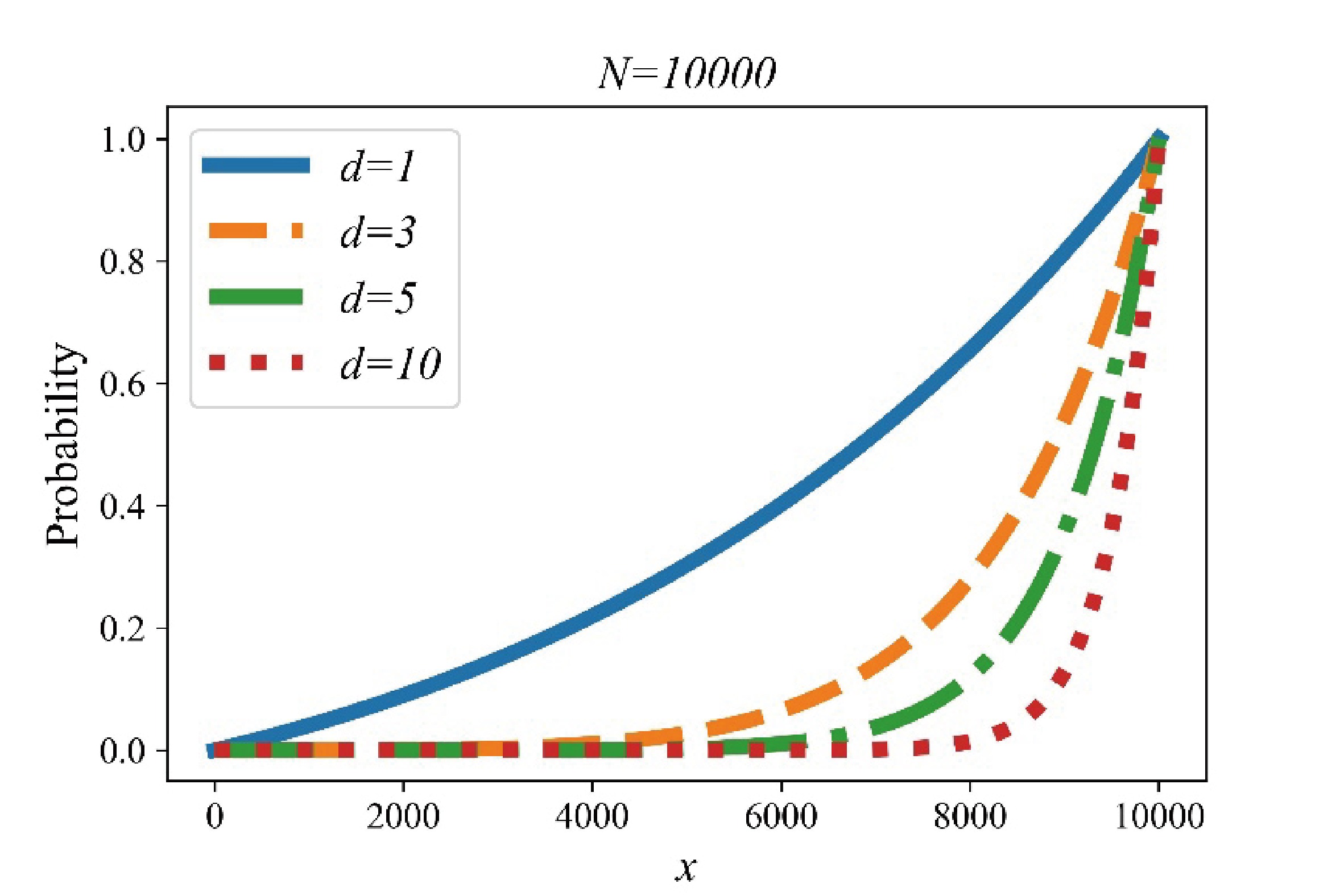
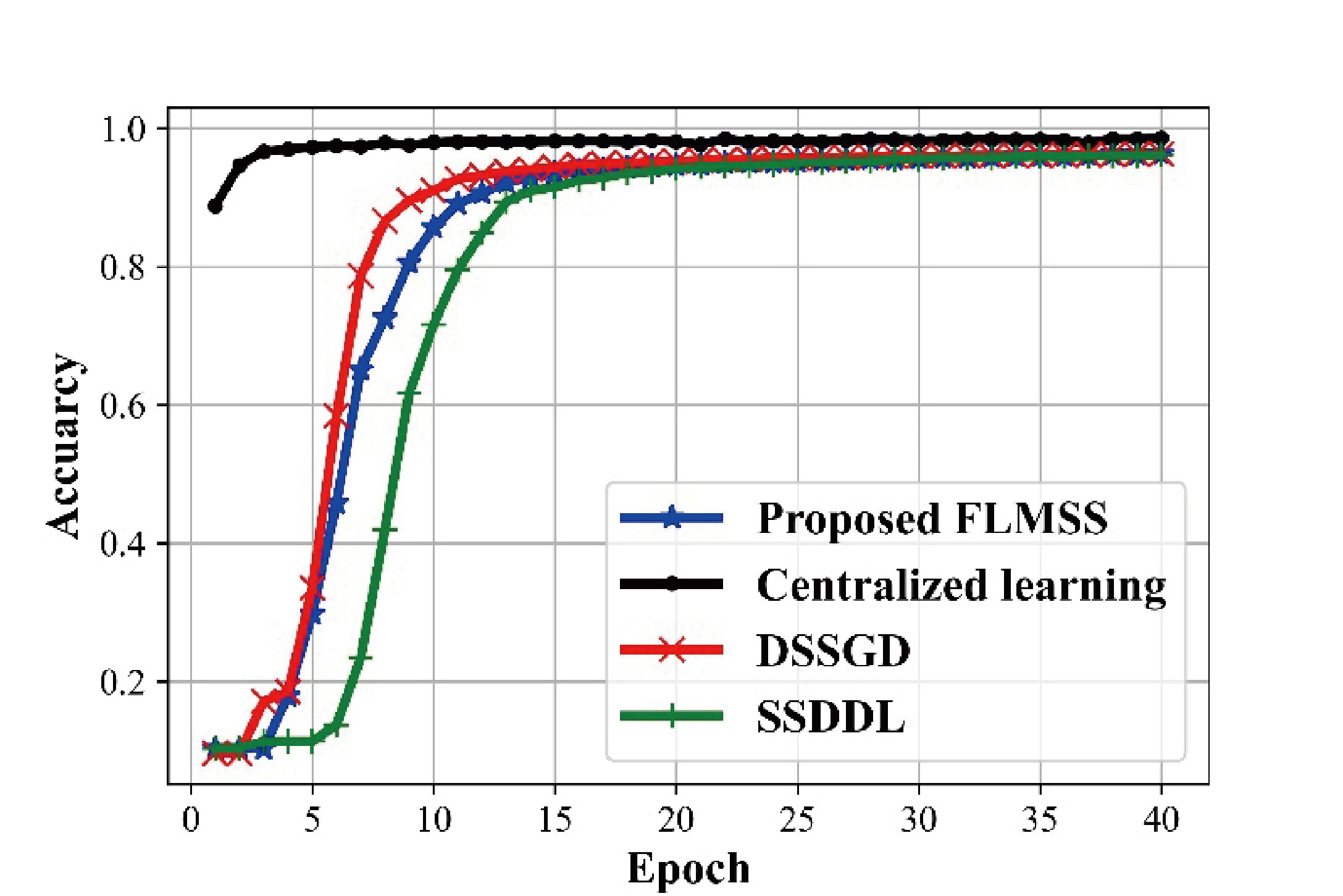
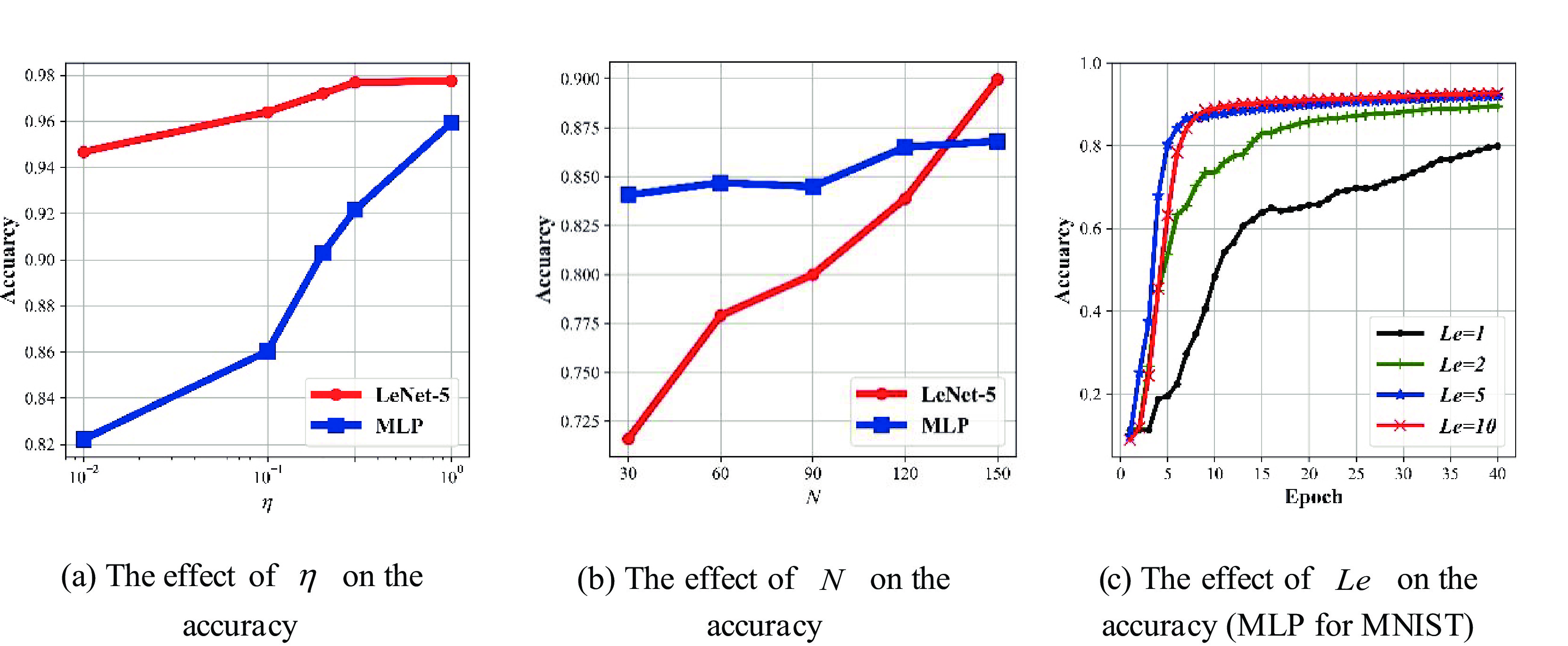
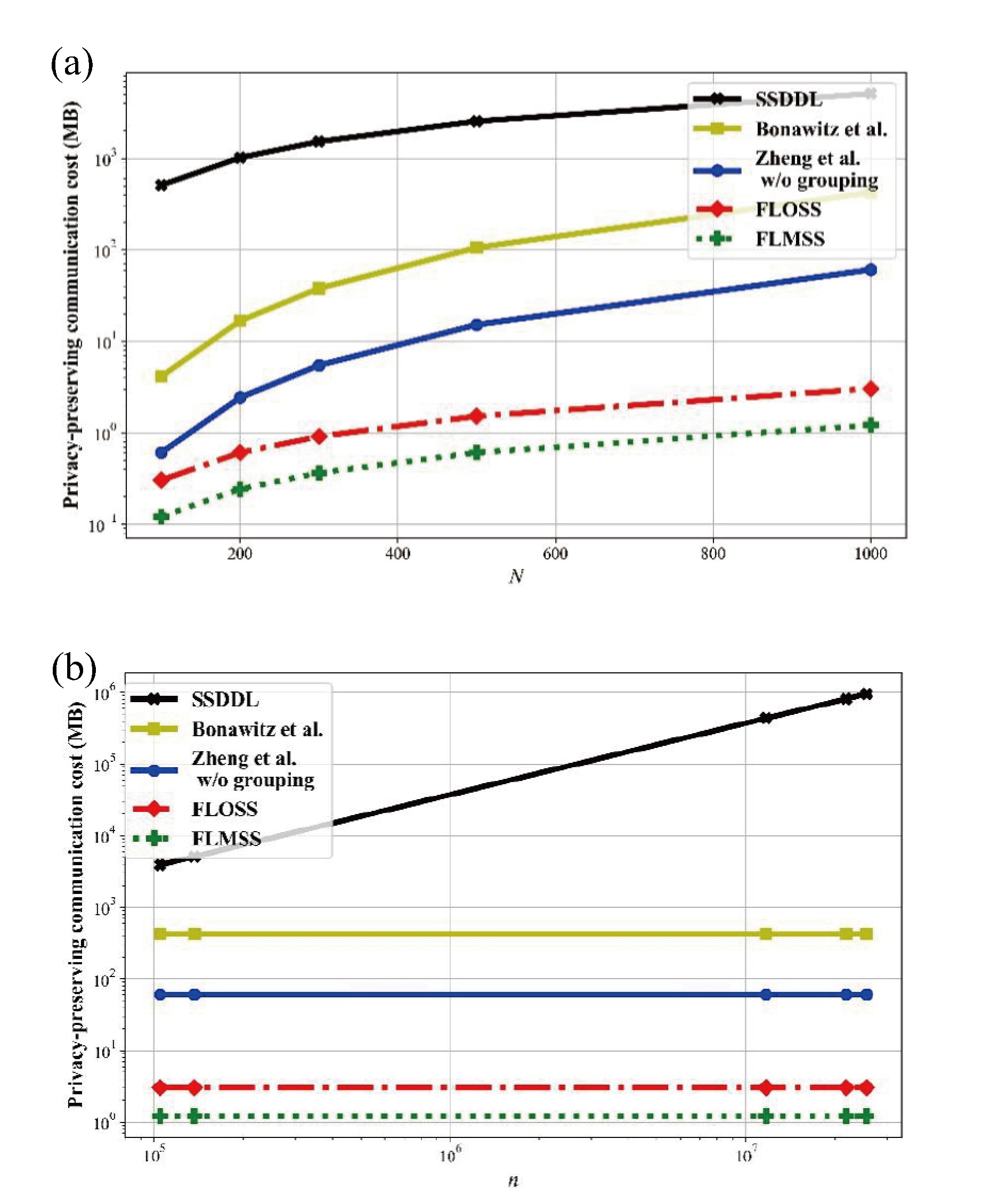
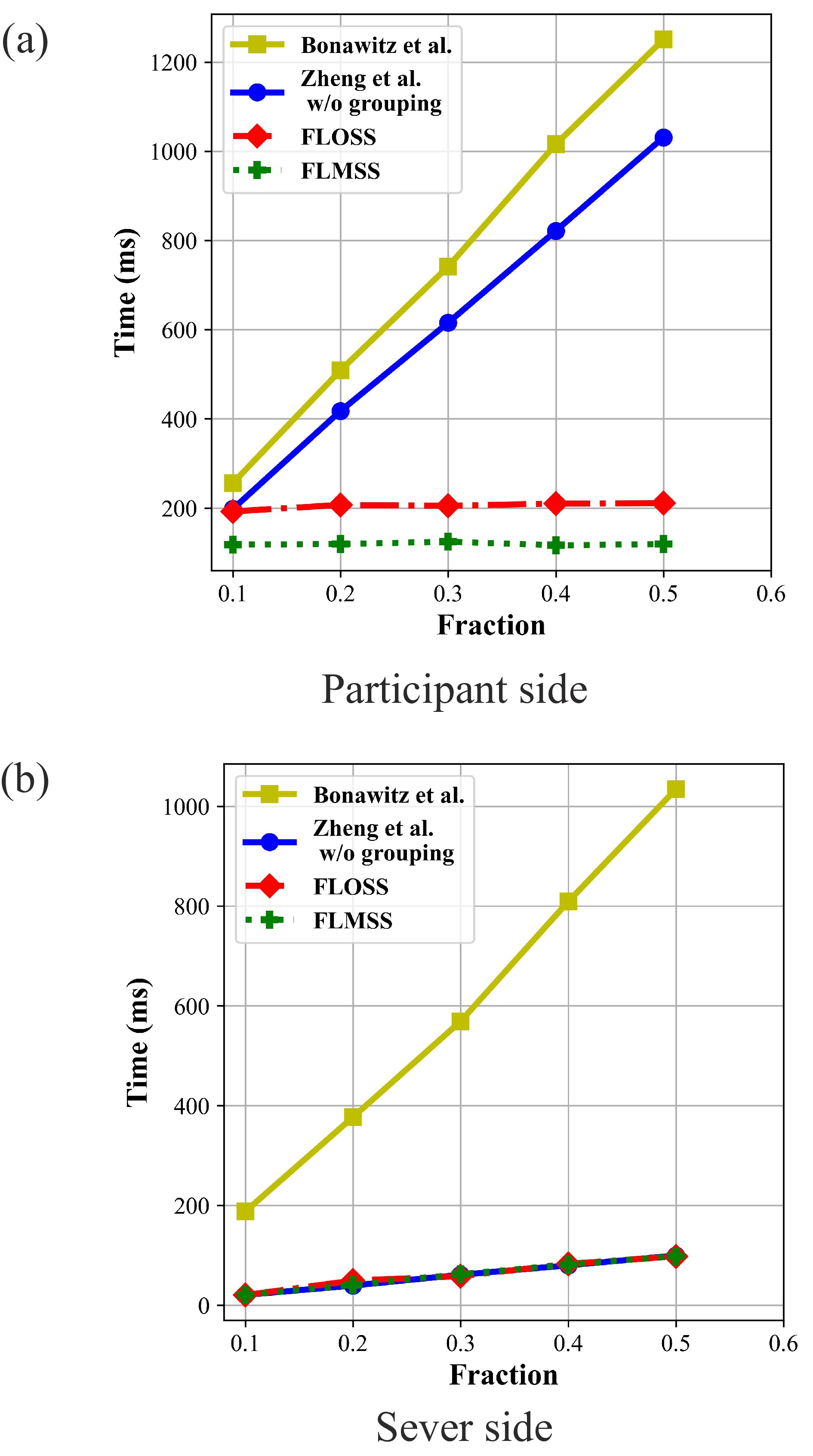
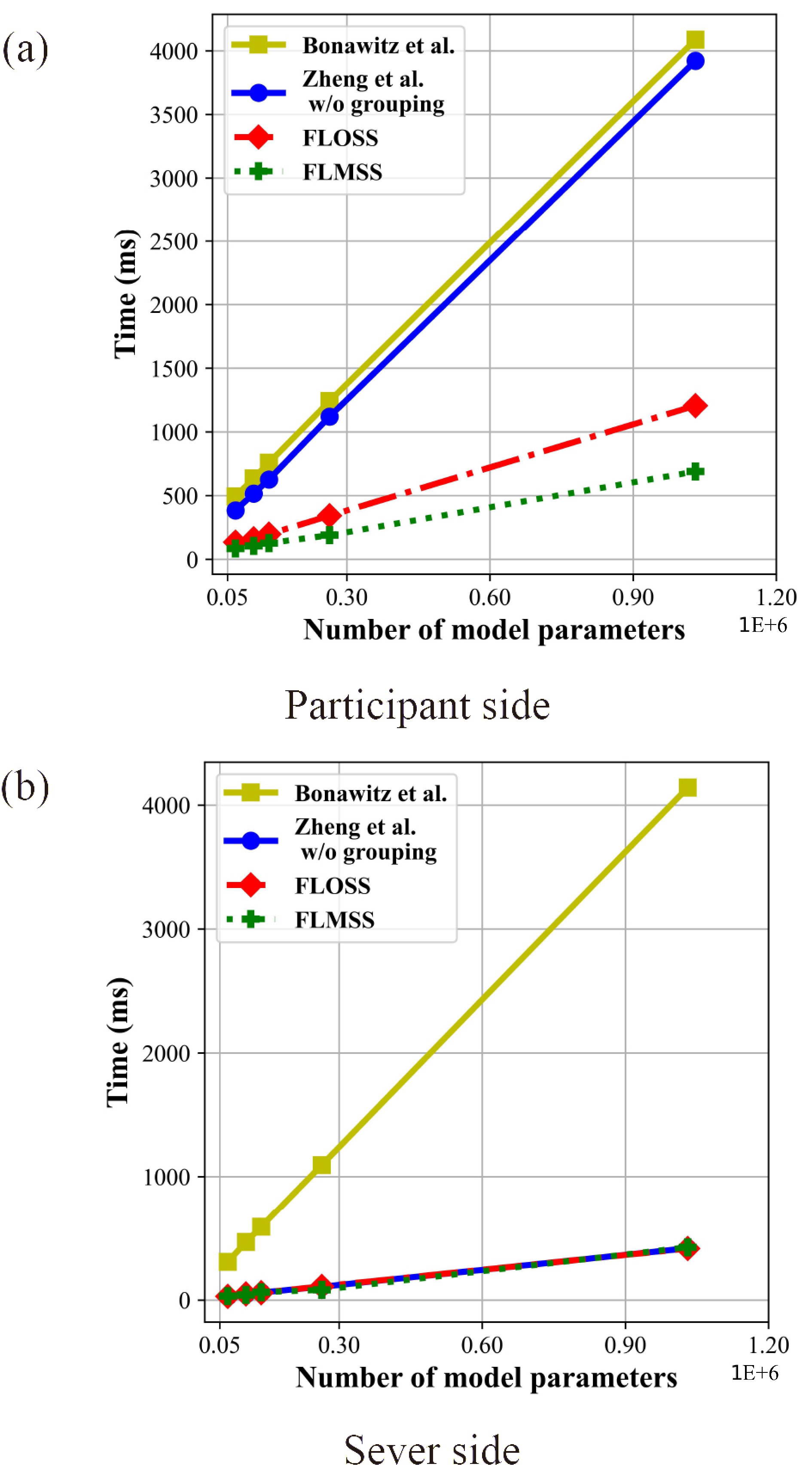
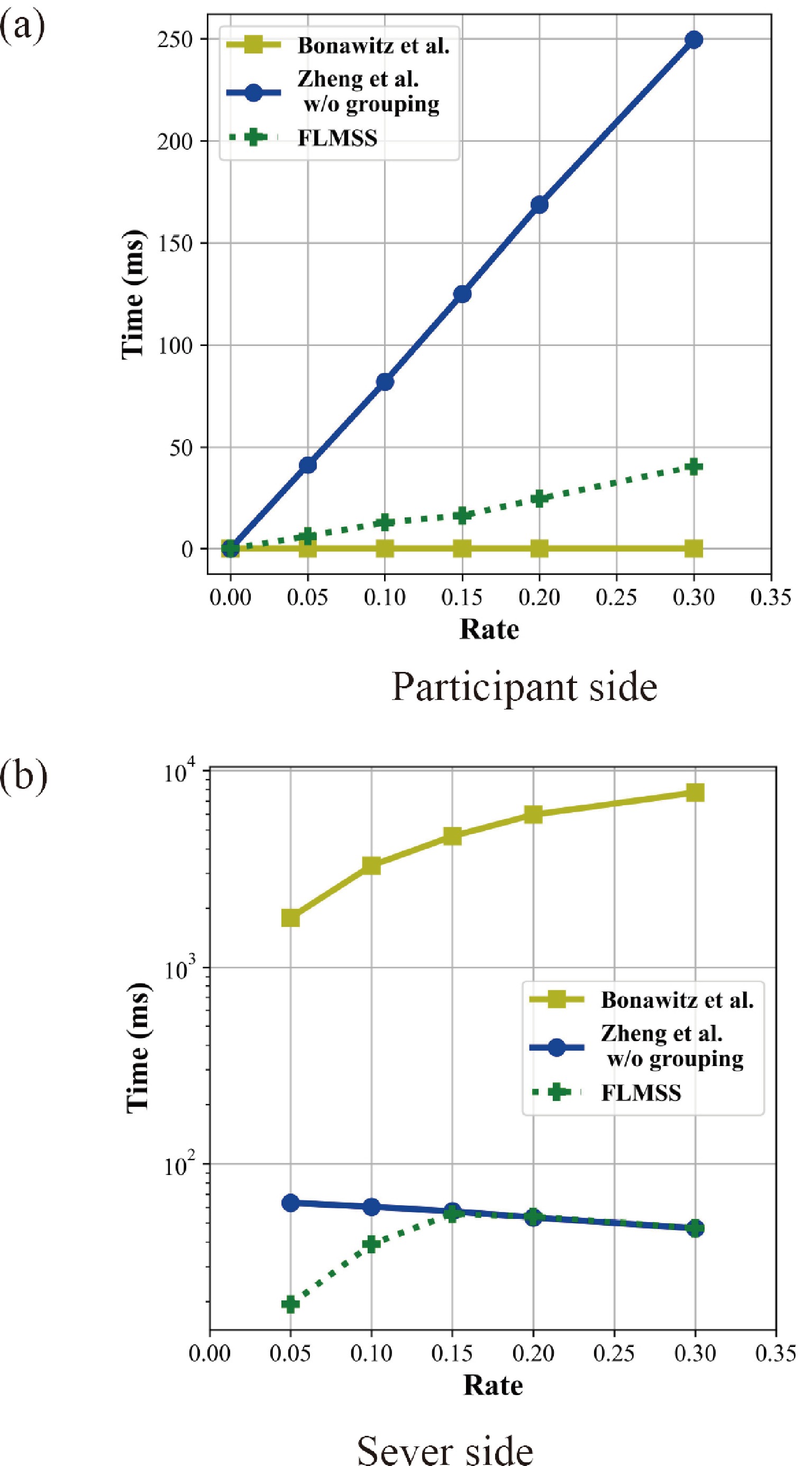
Federated learning allows multiple mobile participants to jointly train a global model without revealing their local private data. Communication-computation cost and privacy preservation are key fundamental issues in federated learning. Existing secret sharing-based secure aggregation mechanisms for federated learning still suffer from significant additional costs, insufficient privacy preservation, and vulnerability to participant dropouts. In this paper, we aim to solve these issues by introducing flexible and effective secret sharing mechanisms into federated learning. We propose two novel privacy-preserving federated learning schemes: federated learning based on one-way secret sharing (FLOSS) and federated learning based on multi-shot secret sharing (FLMSS). Compared with the state-of-the-art works, FLOSS enables high privacy preservation while significantly reducing the communication cost by dynamically designing secretly shared content and objects. Meanwhile, FLMSS further reduces the additional cost and has the ability to efficiently enhance the robustness of participant dropouts in federated learning. Foremost, FLMSS achieves a satisfactory tradeoff between privacy preservation and communication-computation cost. Security analysis and performance evaluations on real datasets demonstrate the superiority of our proposed schemes in terms of model accuracy, privacy preservation, and cost reduction.
Federated learning allows multiple mobile participants to jointly train a global model without revealing their local private data. Communication-computation cost and privacy preservation are key fundamental issues in federated learning. Existing secret sharing-based secure aggregation mechanisms for federated learning still suffer from significant additional costs, insufficient privacy preservation, and vulnerability to participant dropouts. In this paper, we aim to solve these issues by introducing flexible and effective secret sharing mechanisms into federated learning. We propose two novel privacy-preserving federated learning schemes: federated learning based on one-way secret sharing (FLOSS) and federated learning based on multi-shot secret sharing (FLMSS). Compared with the state-of-the-art works, FLOSS enables high privacy preservation while significantly reducing the communication cost by dynamically designing secretly shared content and objects. Meanwhile, FLMSS further reduces the additional cost and has the ability to efficiently enhance the robustness of participant dropouts in federated learning. Foremost, FLMSS achieves a satisfactory tradeoff between privacy preservation and communication-computation cost. Security analysis and performance evaluations on real datasets demonstrate the superiority of our proposed schemes in terms of model accuracy, privacy preservation, and cost reduction.
2024,
54(1):
0105.
doi: 10.52396/JUSTC-2022-0161
Abstract:
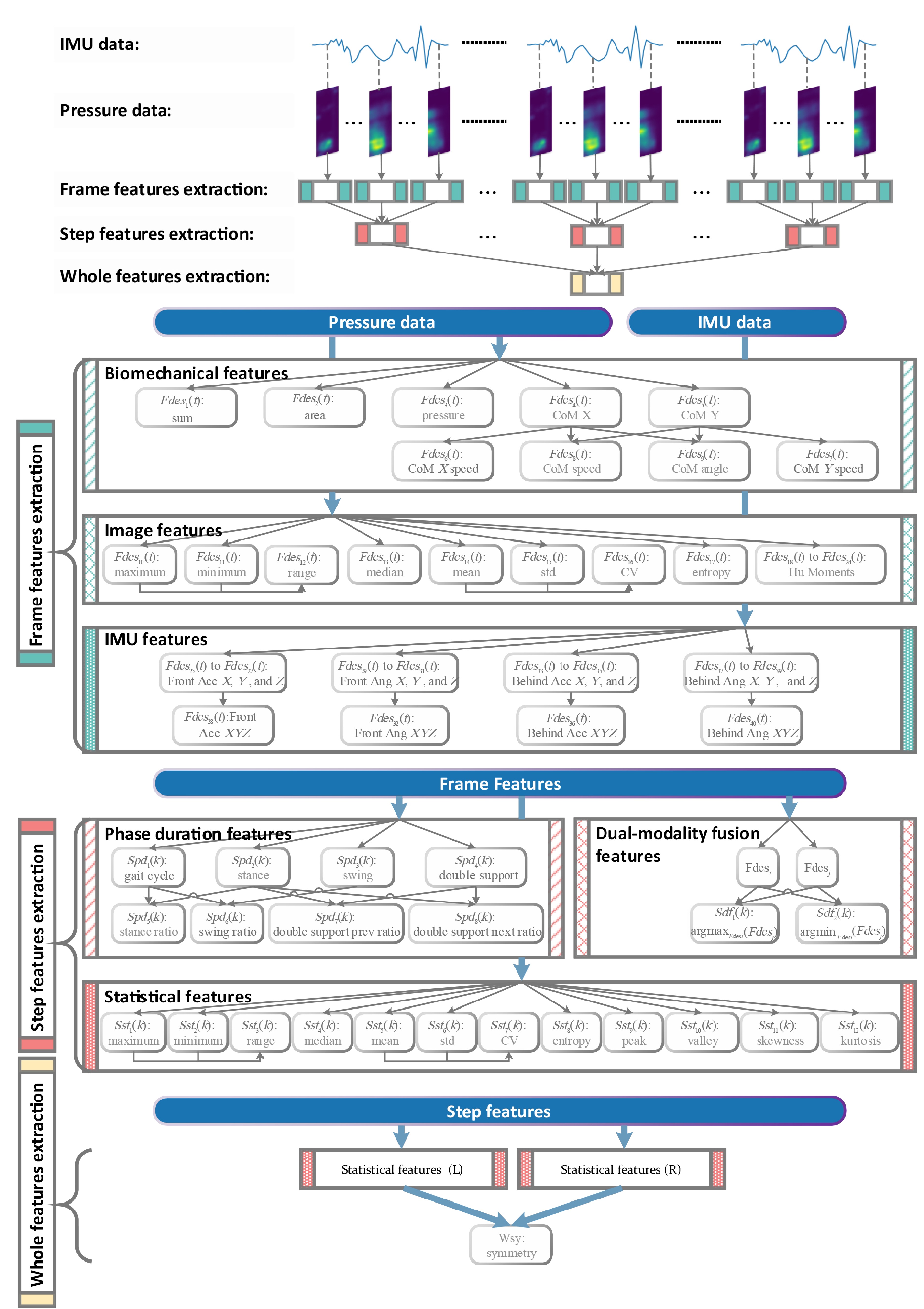
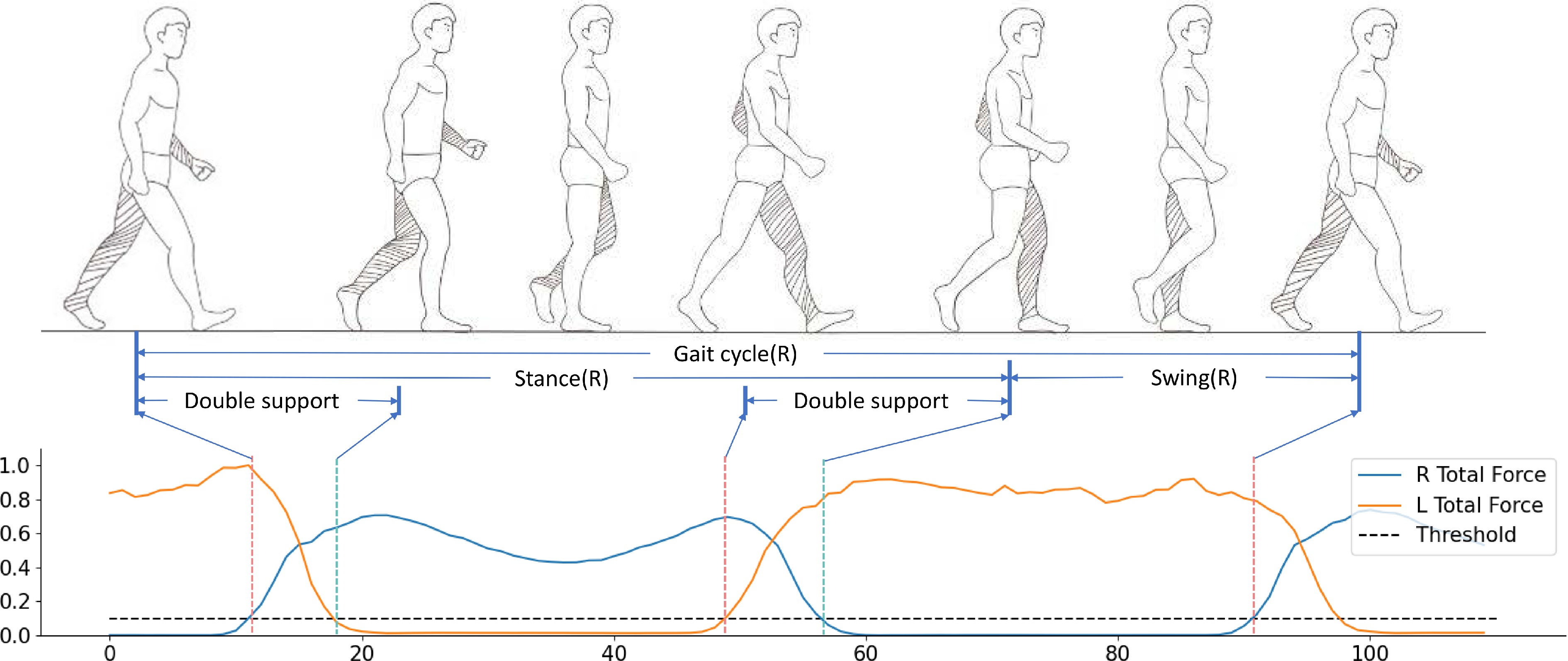
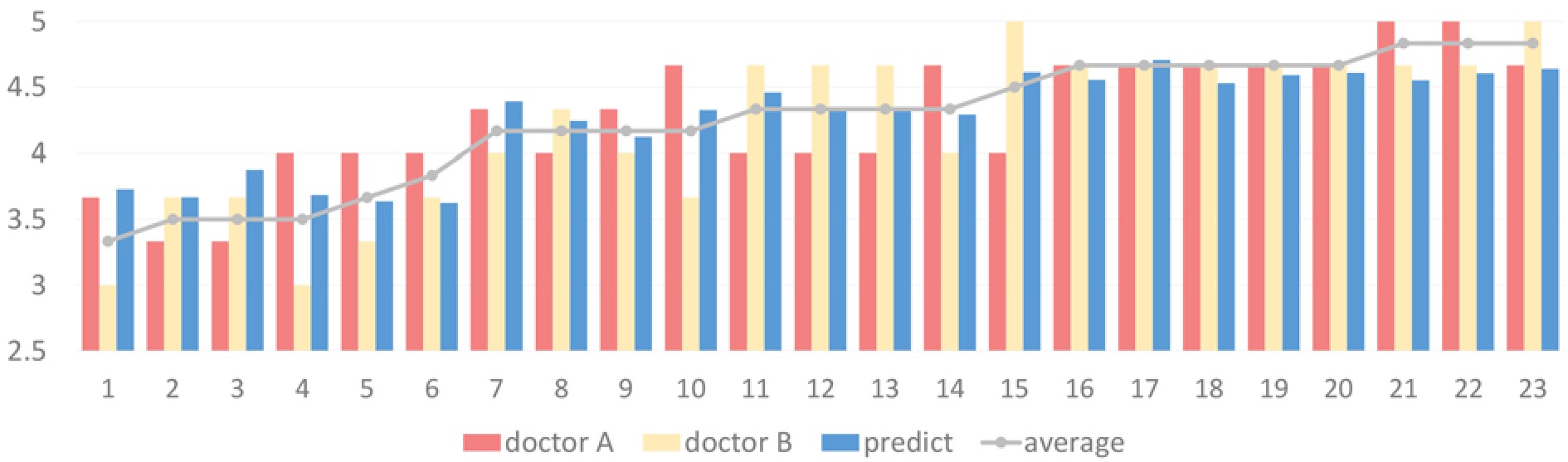
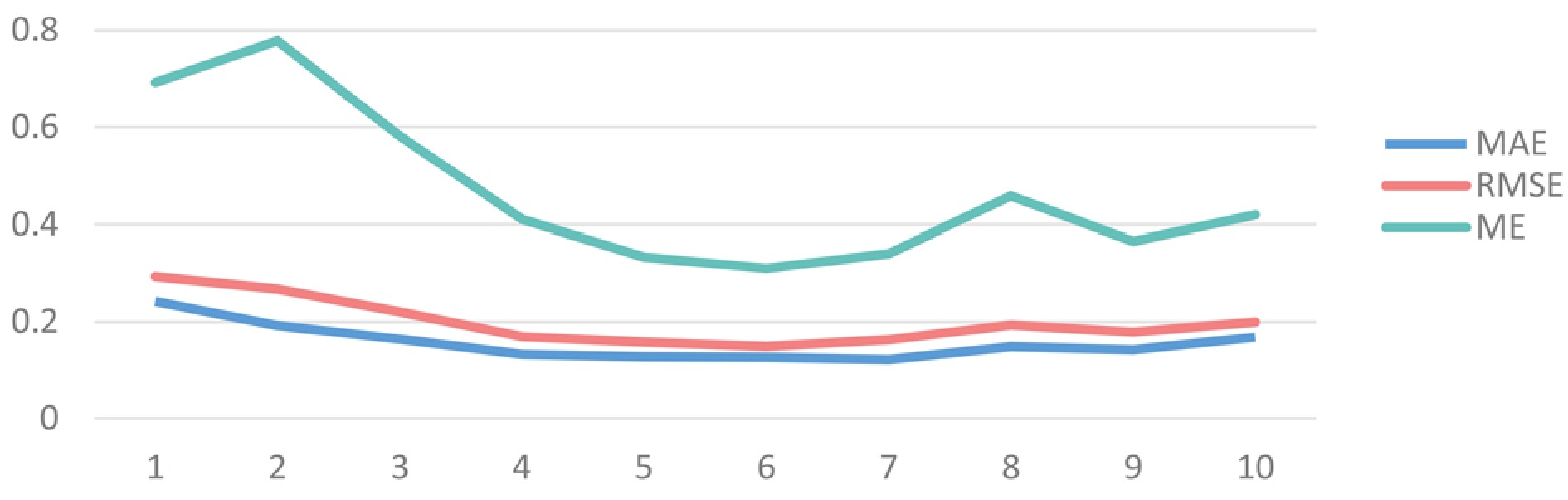
Stroke can lead to the impaired motor function in patients’ lower limbs and hemiplegia. Accurate assessment of lower limb motor ability is important for diagnosis and rehabilitation. To digitalize such assessments so that each test can be traced back at any time and subjectivity can be avoided, we test how dual-modality smart shoes equipped with pressure-sensitive insoles and inertial measurement units can be used for this purpose. A 5 m walking test protocol, including the left and right turns, is designed. The data are collected from 23 patients and 17 healthy subjects. For the lower limbs’ motor ability, the tests are performed by two physicians and assessed using the five-grade Medical Research Council scale for muscle examination. The average of two physicians’ scores for the same patient is used as the ground truth. Using the feature set we developed, 100% accuracy is achieved in classifying the patients and healthy subjects. For patients’ muscle strength, a mean absolute error of 0.143 and a maximum error of 0.395 are achieved using our feature set and the regression method; these values are closer to the ground truth than the scores from each physician (mean absolute error: 0.217, maximum error: 0.5). We thus validate the possibility of using such smart shoes to objectively and accurately evaluate the muscle strength of the lower limbs of stroke patients.
Stroke can lead to the impaired motor function in patients’ lower limbs and hemiplegia. Accurate assessment of lower limb motor ability is important for diagnosis and rehabilitation. To digitalize such assessments so that each test can be traced back at any time and subjectivity can be avoided, we test how dual-modality smart shoes equipped with pressure-sensitive insoles and inertial measurement units can be used for this purpose. A 5 m walking test protocol, including the left and right turns, is designed. The data are collected from 23 patients and 17 healthy subjects. For the lower limbs’ motor ability, the tests are performed by two physicians and assessed using the five-grade Medical Research Council scale for muscle examination. The average of two physicians’ scores for the same patient is used as the ground truth. Using the feature set we developed, 100% accuracy is achieved in classifying the patients and healthy subjects. For patients’ muscle strength, a mean absolute error of 0.143 and a maximum error of 0.395 are achieved using our feature set and the regression method; these values are closer to the ground truth than the scores from each physician (mean absolute error: 0.217, maximum error: 0.5). We thus validate the possibility of using such smart shoes to objectively and accurately evaluate the muscle strength of the lower limbs of stroke patients.

- First
- Prev
- 1
- 2
- Next
- Last
- Total:2
- To
- Go


