 Download:
Download:
Figures of the Article
-
![]() Example video sequences in the MARS and iLIDS-VID person re-identification datasets.
Example video sequences in the MARS and iLIDS-VID person re-identification datasets.
-
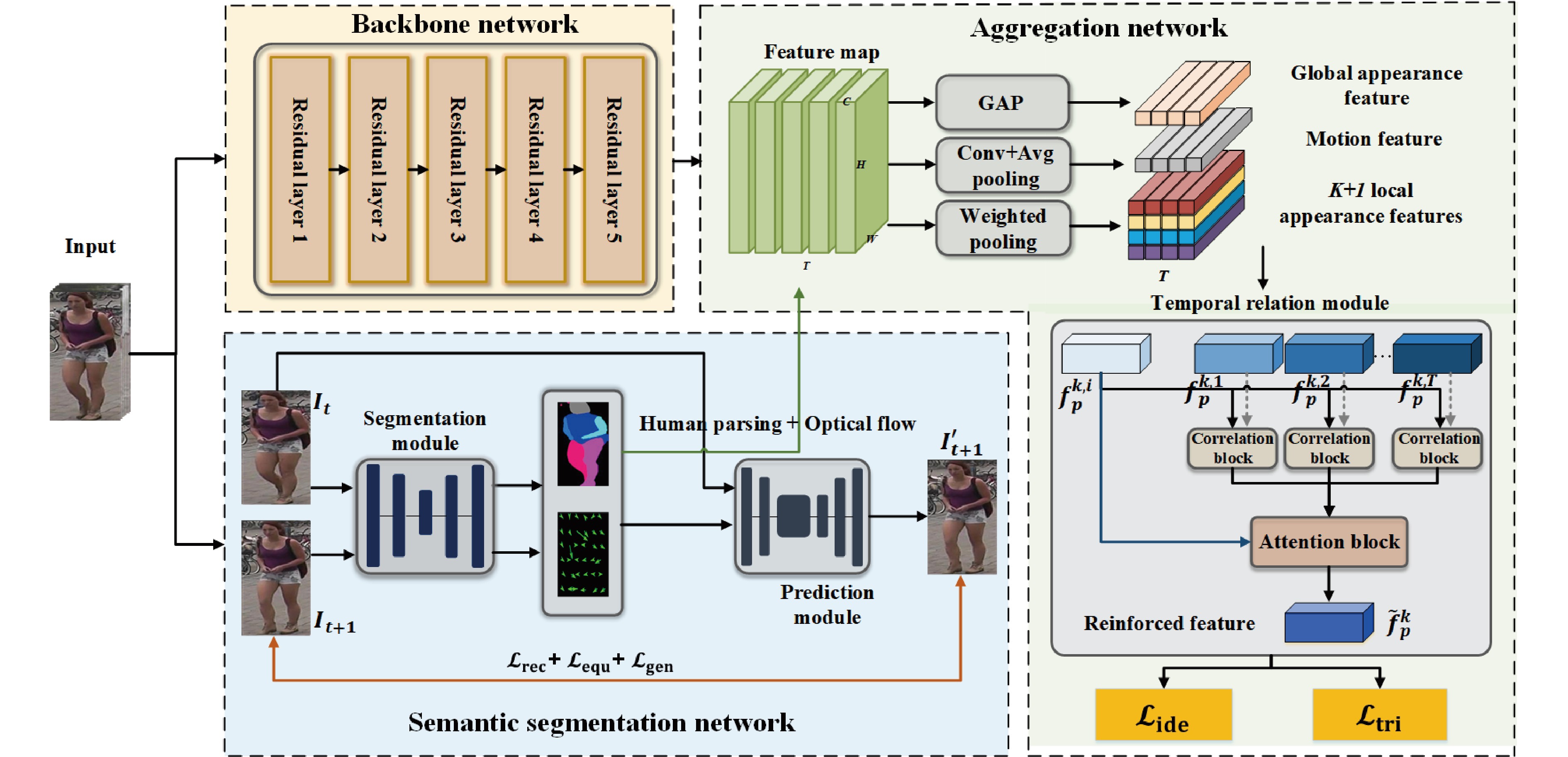
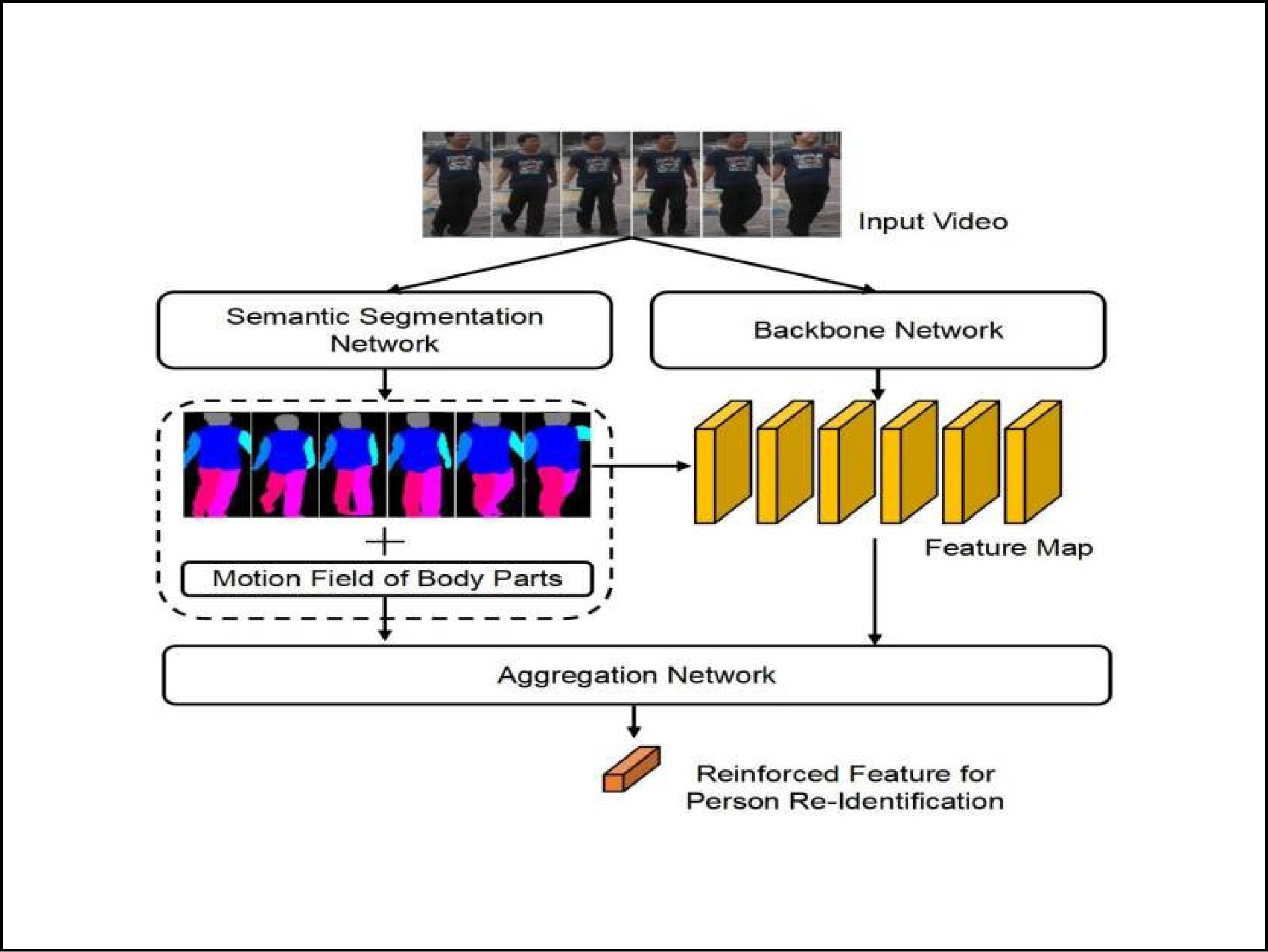
![]() The overall architecture of the proposed SS-HSP. It consists of a backbone network, a semantic segmentation network as well as an aggregation network.
The overall architecture of the proposed SS-HSP. It consists of a backbone network, a semantic segmentation network as well as an aggregation network.
-
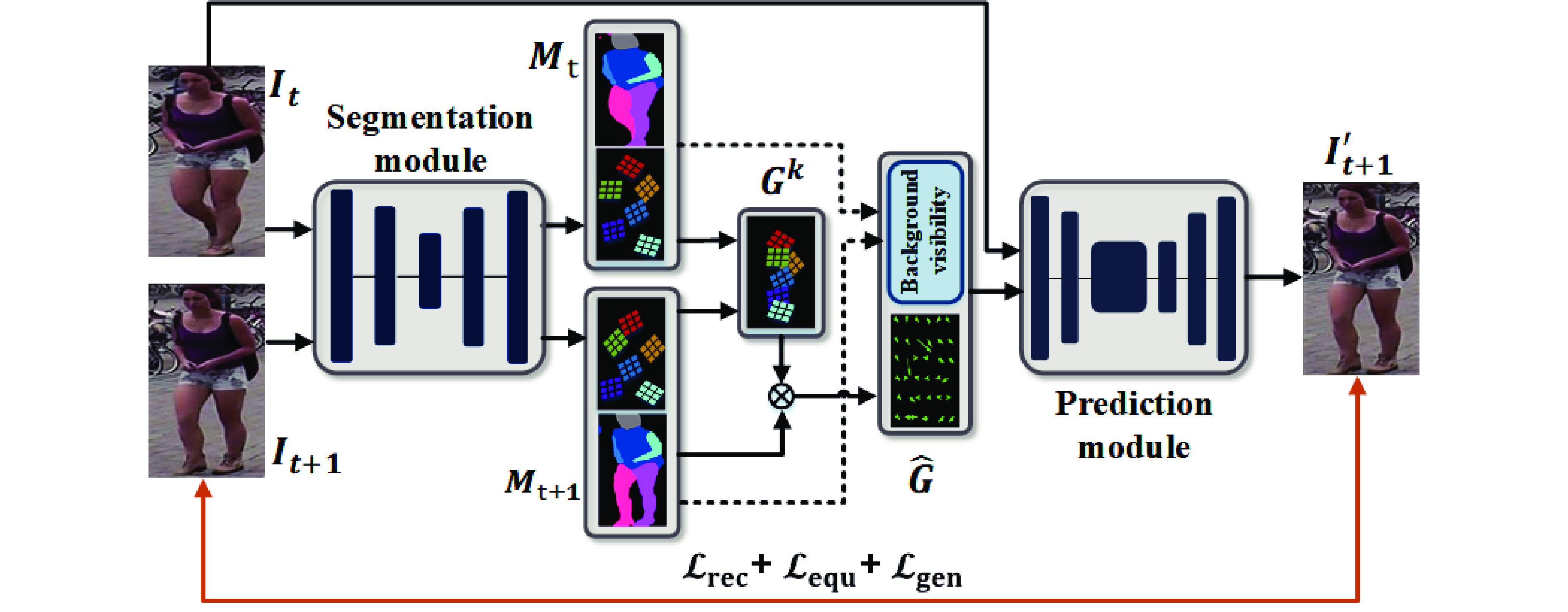
![]() Detailed structure of the semantic segmentation network.
Detailed structure of the semantic segmentation network.
-
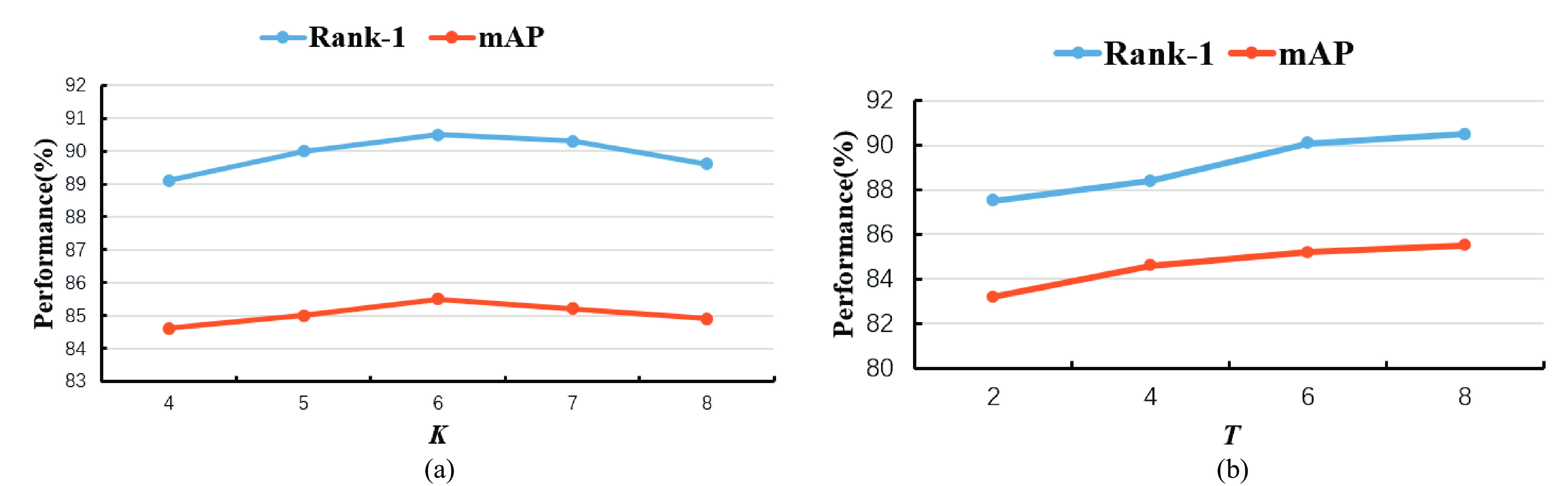
![]() Parameter analysis of (a) the number of body parts
Parameter analysis of (a) the number of body parts $ K $ and (b) the sequence length$ T $ on the MARS dataset. -
![]() Visualization results of the estimated segmentation maps of two video sequences.
Visualization results of the estimated segmentation maps of two video sequences.
-
![]() Example of retrieval results by SS-HSP on MARS dataset. Correct matches are highlighted red.
Example of retrieval results by SS-HSP on MARS dataset. Correct matches are highlighted red.