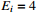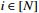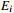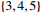Figure
1.
Flow chart for the mean score methodology.
From a statistical viewpoint, it is essential to perform statistical inference in federated learning to understand the underlying data distribution. Due to the heterogeneity in the number of local iterations and in local datasets, traditional statistical inference methods are not competent in federated learning. This paper studies how to construct confidence intervals for federated heterogeneous optimization problems. We introduce the rescaled federated averaging estimate and prove the consistency of the estimate. Focusing on confidence interval estimation, we establish the asymptotic normality of the parameter estimate produced by our algorithm and show that the asymptotic covariance is inversely proportional to the client participation rate. We propose an online confidence interval estimation method called separated plug-in via rescaled federated averaging. This method can construct valid confidence intervals online when the number of local iterations is different across clients. Since there are variations in clients and local datasets, the heterogeneity in the number of local iterations is common. Consequently, confidence interval estimation for federated heterogeneous optimization problems is of great significance.
An online confidence interval estimation method called separated plug-in via rescaled federated averaging.
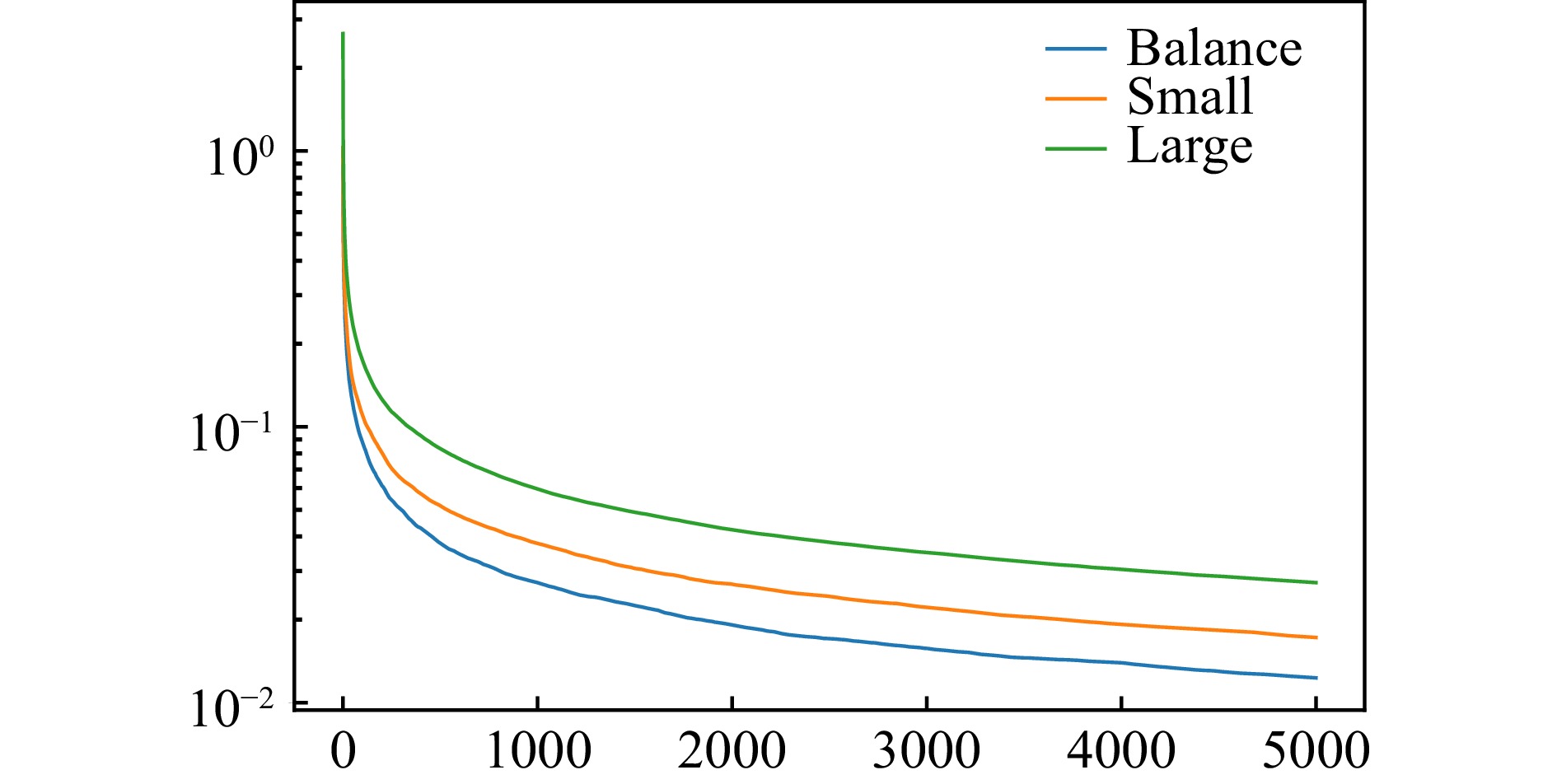
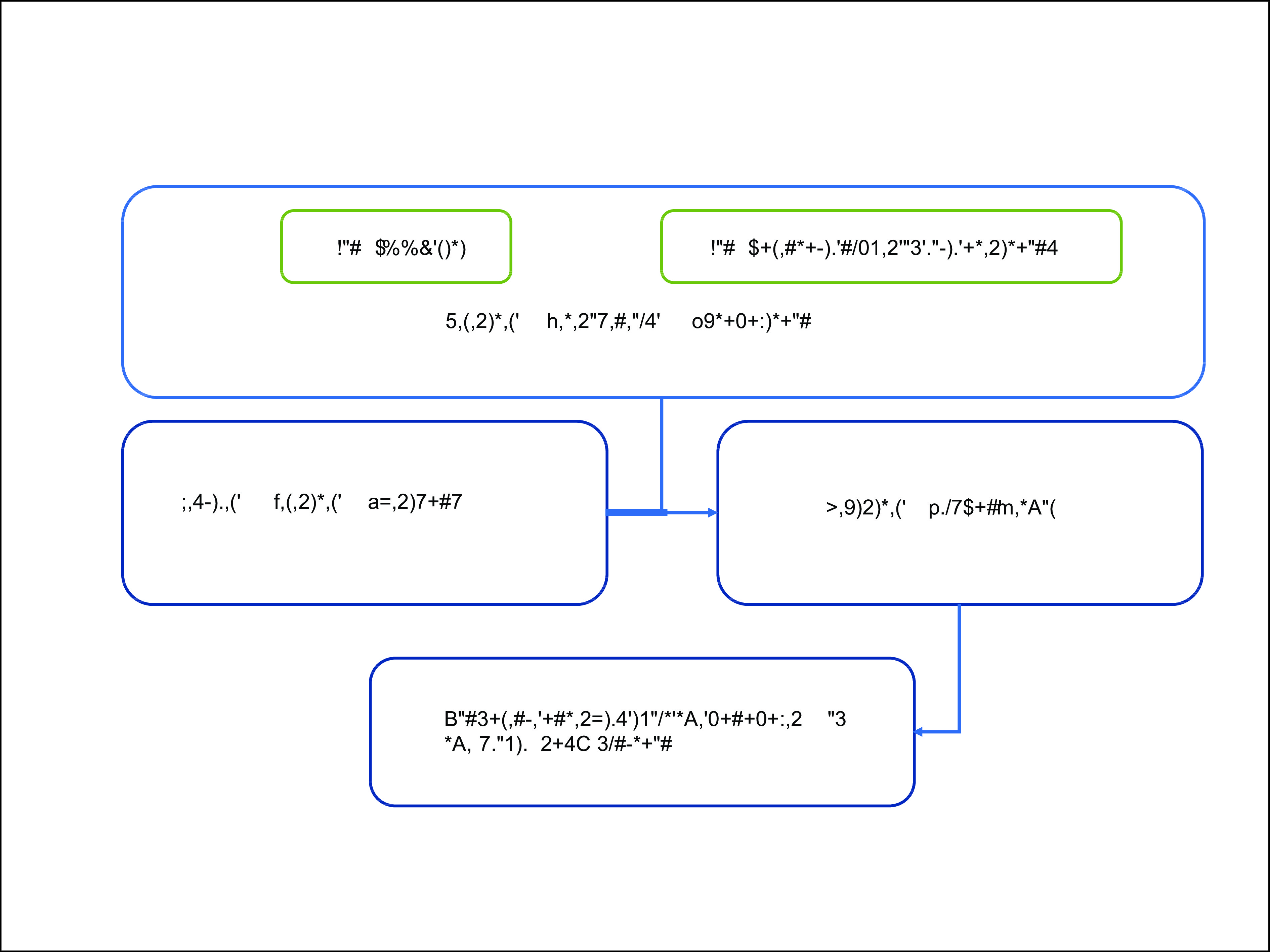
Figure
1.
Impacts of
| [1] |
Hastie T, Friedman J, Tibshirani R. The Elements of Statistical Learning: Data Mining, Inference, and Prediction. New York: Springer, 2001.
|
| [2] |
Berk R A. Statistical Learning from a Regression Perspective. New York: Springer, 2008.
|
| [3] |
James G, Witten D, Hastie T, et al. An Introduction to Statistical Learning: With Applications in R. New York: Springer, 2013.
|
| [4] |
Li T, Sahu A K, Talwalkar A, et al. Federated learning: Challenges, methods, and future directions. IEEE Signal Processing Magazine, 2020, 37 (3): 50–60. DOI: 10.1109/MSP.2020.2975749
|
| [5] |
McMahan B, Moore E, Ramage D, et al. Communication-efficient learning of deep networks from decentralized data. In: Proceedings of the 20th International Conference on Artificial Intelligence and Statistics (AISTATS) 2017. Fort Lauderdale, FL: PMLR, 2017: 1273–1282.
|
| [6] |
Preuveneers D, Rimmer V, Tsingenopoulos I, et al. Chained anomaly detection models for federated learning: An intrusion detection case study. Applied Sciences, 2018, 8 (12): 2663. DOI: 10.3390/app8122663
|
| [7] |
Mothukuri V, Khare P, Parizi R M, et al. Federated-learning-based anomaly detection for IoT security attacks. IEEE Internet of Things Journal, 2021, 9 (4): 2545–2554. DOI: 10.1109/JIOT.2021.3077803
|
| [8] |
Amiri M M, Gündüz D. Federated learning over wireless fading channels. IEEE Transactions on Wireless Communications, 2020, 19: 3546–3557. DOI: 10.1109/TWC.2020.2974748
|
| [9] |
Bharadhwaj H. Meta-learning for user cold-start recommendation. In: 2019 International Joint Conference on Neural Networks (IJCNN). Budapest, Hungary: IEEE, 2019: 1–8.
|
| [10] |
Chen S, Xue D, Chuai G, et al. FL-QSAR: A federated learning-based QSAR prototype for collaborative drug discovery. Bioinformatics, 2021, 36: 5492–5498. DOI: 10.1093/bioinformatics/btaa1006
|
| [11] |
Tarcar A K. Advancing healthcare solutions with federated learning. In: Federated Learning. Cham, Switzerland: Springer, 2022: 499–508.
|
| [12] |
Zhao Y, Li M, Lai L, et al. Federated learning with non-IID data. arXiv: 1806.00582, 2018.
|
| [13] |
Zhang W, Wang X, Zhou P, et al. Client selection for federated learning with non-IID data in mobile edge computing. IEEE Access, 2021, 9: 24462–24474. DOI: 10.1109/ACCESS.2021.3056919
|
| [14] |
Briggs C, Fan Z, Andras P. Federated learning with hierarchical clustering of local updates to improve training on non-IID data. In: 2020 International Joint Conference on Neural Networks (IJCNN). Glasgow, UK: IEEE, 2020: 1–9.
|
| [15] |
Li X, Huang K, Yang W, et al. On the convergence of FedAvg on non-IID data. In: 2020 International Conference on Learning Representations. Appleton, WI: ICLR, 2020.
|
| [16] |
Stich S U. Local SGD converges fast and communicates little. arXiv: 1805.09767, 2018.
|
| [17] |
Zhou F, Cong G. On the convergence properties of a K-step averaging stochastic gradient descent algorithm for nonconvex optimization. In: Proceedings of the 27th International Joint Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2018: 3219–3227.
|
| [18] |
Wang S, Tuor T, Salonidis T, et al. Adaptive federated learning in resource constrained edge computing systems. IEEE Journal on Selected Areas in Communications, 2019, 37 (6): 1205–1221. DOI: 10.1109/JSAC.2019.2904348
|
| [19] |
Yu H, Jin R, Yang S. On the linear speedup analysis of communication efficient momentum SGD for distributed non-convex optimization. In: Proceedings of the 36th International Conference on Machine Learning. Long Beach, CA: PMLR, 2019: 7184–7193.
|
| [20] |
Wang J, Liu Q, Liang H, et al. Tackling the objective inconsistency problem in heterogeneous federated optimization. In: Advances in Neural Information Processing Systems 33 (NeurIPS 2020). Red Hook, NY: Curran Associates, Inc., 2020, 33: 7611–7623.
|
| [21] |
Li T, Sahu A K, Zaheer M, et al. Federated optimization in heterogeneous networks. In: Proceedings of Machine Learning and Systems 2020 (MLSys 2020). Austin, TX: mlsys.org, 2020, 2: 429–450.
|
| [22] |
Karimireddy S P, Kale S, Mohri M, et al. SCAFFOLD: Stochastic controlled averaging for federated learning. In: Proceedings of the 37th International Conference on Machine Learning. Online: PMLR, 2020: 5132–5143.
|
| [23] |
Liang X, Shen S, Liu J, et al. Variance reduced local SGD with lower communication complexity. arXiv: 1912.12844, 2019.
|
| [24] |
Ruppert D. Efficient estimations from a slowly convergent Robbins–Monro process. Ithaca, New York: Cornell University, 1988.
|
| [25] |
Polyak B T, Juditsky A B. Acceleration of stochastic approximation by averaging. SIAM Journal on Control and Optimization, 1992, 30 (4): 838–855. DOI: 10.1137/0330046
|
| [26] |
Zhu W, Chen X, Wu W. Online covariance matrix estimation in stochastic gradient descent. Journal of the American Statistical Association, 2021, 118: 393–404. DOI: 10.1080/01621459.2021.1933498
|
| [27] |
Fang Y, Xu J, Yang L. Online bootstrap confidence intervals for the stochastic gradient descent estimator. The Journal of Machine Learning Research, 2018, 19 (1): 3053–3073. DOI: 10.5555/3291125.3309640
|
| [28] |
Li X, Liang J, Chang X, et al. Statistical estimation and online inference via local SGD. In: Proceedings of Thirty Fifth Conference on Learning Theory. London: PMLR, 2022: 1613–1661.
|
| [29] |
Su W J, Zhu Y. Uncertainty quantification for online learning and stochastic approximation via hierarchical incremental gradient descent. arXiv: 1802.04876, 2018.
|
| [30] |
Reisizadeh A, Mokhtari A, Hassani H, et al. FedPAQ: A communication-efficient federated learning method with periodic averaging and quantization. In: Proceedings of the 23rd International Conference on Artificial Intelligence and Statistics (AISTATS) 2020. Palermo, Italy: PMLR, 2020, 108: 2021–2031.
|
| [31] |
Khaled A, Mishchenko K, Richtárik P. First analysis of local GD on heterogeneous data. arXiv: 1909.04715, 2019.
|
| [32] |
Nesterov Y. Introductory Lectures on Convex Optimization: A Basic Course. New York: Springer, 2003.
|
| [33] |
Toulis P, Airoldi E M. Asymptotic and finite-sample properties of estimators based on stochastic gradients. The Annals of Statistics, 2017, 45 (4): 1694–1727. DOI: 10.1214/16-AOS1506
|
| [34] |
Chen X, Lee J D, Tong X T, et al. Statistical inference for model parameters in stochastic gradient descent. The Annals of Statistics, 2020, 48 (1): 251–273. DOI: 10.1214/18-AOS1801
|
| [35] |
Liu R, Yuan M, Shang Z. Online statistical inference for parameters estimation with linear-equality constraints. Journal of Multivariate Analysis, 2022, 191: 105017. DOI: 10.1016/j.jmva.2022.105017
|
| [36] |
Lee S, Liao Y, Seo M H, et al. Fast and robust online inference with stochastic gradient descent via random scaling. Proceedings of the AAAI Conference on Artificial Intelligence, 2022, 36 (7): 7381–7389. DOI: 10.1609/aaai.v36i7.20701
|
| [37] |
Salam A, El Hibaoui A. Comparison of machine learning algorithms for the power consumption prediction: Case study of Tetouan city. In: 2018 6th International Renewable and Sustainable Energy Conference (IRSEC). Rabat, Morocco: IEEE, 2018.
|
| [38] |
Hall P, Heyde C C. Martingale Limit Theory and Its Application. New York: Academic Press, 2014.
|

ISSN 0253-2778
CN 34-1054/N
Copyright © Editorial Office of JUSTC, All Rights Reserved. 皖ICP备05002528号
Supported by: Beijing Renhe Information Technology Co., Ltd. 
| Scenarios | Type Ⅰ Linear regression and regularization | Type Ⅱ | Type Ⅲ | Type Ⅳ | Mean | ||||||||||
| Linear | Ridge | LASSO | EN | Pearson | MIC | SVR-RFE | RF-RFE | RF | GBR | ||||||
| AMSE | Overfitting (p=100, n=30) | 0.106 | 0.106 | 0.127 | 0.120 | 0.125 | 0.105 | 0.103 | 0.102 | 0.133 | 0.131 | 0.105 | |||
| Underfitting in small dataset (p=20, n=100) | 0.120 | 0.120 | 0.909 | 0.737 | 0.127 | 0.116 | 0.175 | 0.232 | 0.121 | 0.120 | 0.118 | ||||
| Underfitting in big dataset (p=100, n=1000) | 0.108 | 0.108 | 1.000 | 0.882 | 0.134 | 0.101 | 0.101 | 0.100 | 0.125 | 0.107 | 0.102 | ||||
| AMAE | Overfitting (p=100, n=30) | 0.213 | 0.212 | 0.268 | 0.244 | 0.247 | 0.210 | 0.206 | 0.205 | 0.268 | 0.278 | 0.210 | |||
| Underfitting in small dataset (p=20, n=100) | 0.249 | 0.249 | 0.924 | 0.780 | 0.270 | 0.242 | 0.291 | 0.339 | 0.252 | 0.249 | 0.246 | ||||
| Underfitting in big dataset (p=100, n=1000) | 0.232 | 0.232 | 1.000 | 0.757 | 0.288 | 0.216 | 0.218 | 0.217 | 0.275 | 0.234 | 0.221 | ||||
 DownLoad:
CSV
DownLoad:
CSV