| [1] |
Yin W, Zhang J, Wang O, et al. Learning to recover 3D scene shape from a single image. In: 2021 EEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, TN, USA: IEEE, 2021 : 204–213.
|
| [2] |
Ranftl R, Bochkovskiy A, Koltun V. Vision transformers for dense prediction. In: 2021 IEEE/CVF International Conference on Computer Vision (ICCV). Montreal, QC, Canada: IEEE, 2021 : 12159.
|
| [3] |
Ranftl R, Lasinger K, Hafner D, et al. Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44: 1623–1637. doi: 10.1109/tpami.2020.3019967
|
| [4] |
Xian K, Zhang J, Wang O, et al. Structure-guided ranking loss for single image depth prediction. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, WA, USA: IEEE, 2020 : 608–617.
|
| [5] |
Li Z, Snavely N. MegaDepth: Learning single-view depth prediction from Internet photos. In: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT, USA: IEEE, 2018 : 2041–2050.
|
| [6] |
Chen W, Qian S, Fan D, et al. OASIS: A large-scale dataset for single image 3D in the wild. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, WA, USA: IEEE, 2020 : 676–685.
|
| [7] |
Yin W, Liu Y, Shen C. Virtual normal: Enforcing geometric constraints for accurate and robust depth prediction. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44: 7282–7295. doi: 10.1109/tpami.2021.3097396
|
| [8] |
Chen W, Fu Z, Yang D, et al. Single-image depth perception in the wild. In: NIPS'16: Proceedings of the 30th International Conference on Neural Information Processing Systems. New York: ACM , 2016 : 730–738.
|
| [9] |
Bian J W, Zhan H, Wang N, et al. Unsupervised scale-consistent depth learning from video. International Journal of Computer Vision, 2021, 129 (9): 2548–2564. doi: 10.1007/s11263-021-01484-6
|
| [10] |
Wang Y, Chao W L, Garg D, et al. Pseudo-LiDAR from visual depth estimation: Bridging the gap in 3D object detection for autonomous driving. In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA, USA: IEEE, 2019 : 8437–8445.
|
| [11] |
Peng W, Pan H, Liu H, et al. IDA-3D: Instance-depth-aware 3D object detection from stereo vision for autonomous driving. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, WA, USA: IEEE, 2020 : 13012.
|
| [12] |
Huang J, Chen Z, Ceylan D, et al. 6-DOF VR videos with a single 360-camera. In: 2017 IEEE Virtual Reality (VR). Los Angeles, CA, USA: IEEE, 2017 : 37–44.
|
| [13] |
Valentin J, Kowdle A, Barron J T, et al. Depth from motion for smartphone AR. ACM Transactions on Graphics, 2018, 37 (6): 1–19. doi: 10.1145/3272127.3275041
|
| [14] |
Song S, Yu F, Zeng A, et al. Semantic scene completion from a single depth image. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, HI, USA: IEEE, 2017 : 1746–1754.
|
| [15] |
Silberman N, Hoiem D, Kohli P, et al. Indoor segmentation and support inference from RGBD images. In: Fitzgibbon A, Lazebnik S, Perona P, et al., editors. Computer Vision – ECCV 2012. Berlin: Springer, 2012 : 746–760.
|
| [16] |
Song S, Lichtenberg S P, Xiao J. SUN RGB-D: A RGB-D scene understanding benchmark suite. In: 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston, MA, USA: IEEE, 2015 : 567–576.
|
| [17] |
Yang X, Zhou L, Jiang H, et al. Mobile3DRecon: Real-time monocular 3D reconstruction on a mobile phone. IEEE Transactions on Visualization and Computer Graphics, 2020, 26 (12): 3446–3456. doi: 10.1109/tvcg.2020.3023634
|
| [18] |
Azinović D, Martin-Brualla R, Dan B Goldman D, B, et al. Neural RGB-D surface reconstruction. In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New Orleans, LA, USA: IEEE, 2022 : 6280–6291.
|
| [19] |
Eftekhar A, Sax A, Malik J, et al. Omnidata: A scalable pipeline for making multi-task mid-level vision datasets from 3D scans. In: 2021 IEEE/CVF International Conference on Computer Vision (ICCV). Montreal, QC, Canada: IEEE, 2021 : 10766–10776.
|
| [20] |
Bian J W, Zhan H, Wang N, et al. Auto-rectify network for unsupervised indoor depth estimation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44 (12): 9802–9813. doi: 10.1109/tpami.2021.3136220
|
| [21] |
Godard C, Mac Aodha O, Firman M, et al. Digging into self-supervised monocular depth estimation. In: 2019 IEEE/CVF International Conference on Computer Vision (ICCV). Seoul, Korea: IEEE, 2019 : 3827–3837.
|
| [22] |
Watson J, Mac Aodha O, Prisacariu V, et al. The temporal opportunist: Self-supervised multi-frame monocular depth. In: 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, TN, USA: IEEE, 2021 : 1164–1174.
|
| [23] |
Luo X, Huang J B, Szeliski R, et al. Consistent video depth estimation. ACM Transactions on Graphics, 2020, 39 (4): 71. doi: 10.1145/3386569.3392377
|
| [24] |
Kopf J, Rong X, Huang J B. Robust consistent video depth estimation. In: 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, TN, USA: IEEE, 2021 : 1611–1621.
|
| [25] |
Park J, Joo K, Hu Z, et al. Non-local spatial propagation network for depth completion. In: Vedaldi A, Bischof H, Brox T, et al., editors. Computer Vision – ECCV 2020. Cham: Springer, 2020 : 120–136.
|
| [26] |
Wong A, Soatto S. Unsupervised depth completion with calibrated backprojection layers. In: 2021 IEEE/CVF International Conference on Computer Vision (ICCV). Montreal, QC, Canada: IEEE, 2021 : 12727–12736.
|
| [27] |
Wong A, Cicek S, Soatto S. Learning topology from synthetic data for unsupervised depth completion. IEEE Robotics and Automation Letters, 2021, 6 (2): 1495–1502. doi: 10.1109/lra.2021.3058072
|
| [28] |
Yang Y, Wong A, Soatto S. Dense depth posterior (DDP) from single image and sparse range. In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA, USA: IEEE, 2019 : 3348–3357.
|
| [29] |
He K, Zhang X, Ren S, et al. Deep residual learning for image recognition. In: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, NV, USA: IEEE, 2016 : 770–778.
|
| [30] |
Liu Z, Lin Y, Cao Y, et al. Swin transformer: Hierarchical vision transformer using shifted windows. In: 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada: IEEE, 2021 : 9992–10002.
|
| [31] |
Schönberger J L, Frahm J M. Structure-from-motion revisited. In: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, NV, USA: IEEE, 2016 : 4104–4113.
|
| [32] |
Teed Z, Deng J. DeepV2D: Video to depth with differentiable structure from motion. arXiv: 1812.04605, 2018 .
|
| [33] |
Liu C, Gu J, Kim K, et al. Neural RGB@D sensing: Depth and uncertainty from a video camera. In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA: IEEE, 2019 : 10978–10987.
|
| [34] |
Düzçeker A, Galliani S, Vogel C, et al. DeepVideoMVS: Multi-view stereo on video with recurrent spatio-temporal fusion. In: 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, TN, USA: IEEE, 2021 : 15319–15328.
|
| [35] |
Zeng A, Song S, Nießner M, et al. 3DMatch: Learning local geometric descriptors from RGB-D reconstructions. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, HI, USA: IEEE, 2017 : 199–208.
|
| [36] |
Mur-Artal R, Montiel J M M, Tardós J D. ORB-SLAM: A versatile and accurate monocular SLAM system. IEEE Transactions on Robotics, 2015, 31: 1147–1163. doi: 10.1109/tro.2015.2463671
|
| [37] |
Schönberger J L, Zheng E, Frahm J M, et al. Pixelwise view selection for unstructured multi-view stereo. In: European conference on computer vision. Cham: Springer, 2016 : 501–518.
|
| [38] |
Im S, Jeon H G, Lin S, et al. DPSNet: End to-end deep plane sweep stereo. arXiv: 1905.00538, 2019 .
|
| [39] |
Wang C, Lucey S, Perazzi F, et al. Web stereo video supervision for depth prediction from dynamic scenes. In: 2019 International Conference on 3D Vision (3DV). Quebec City, QC, Canada: IEEE, 2019 : 348–357.
|
| [40] |
Chen W, Qian S, Deng J. Learning single-image depth from videos using quality assessment networks. In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA, USA: IEEE, 2019 : 5597–5606.
|
| [41] |
Xie S, Girshick R, Dollár P, et al. Aggregated residual transformations for deep neural networks. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, HI, USA: IEEE, 2017 : 5987–5995.
|
| [42] |
Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv: 2010.11929, 2021 .
|
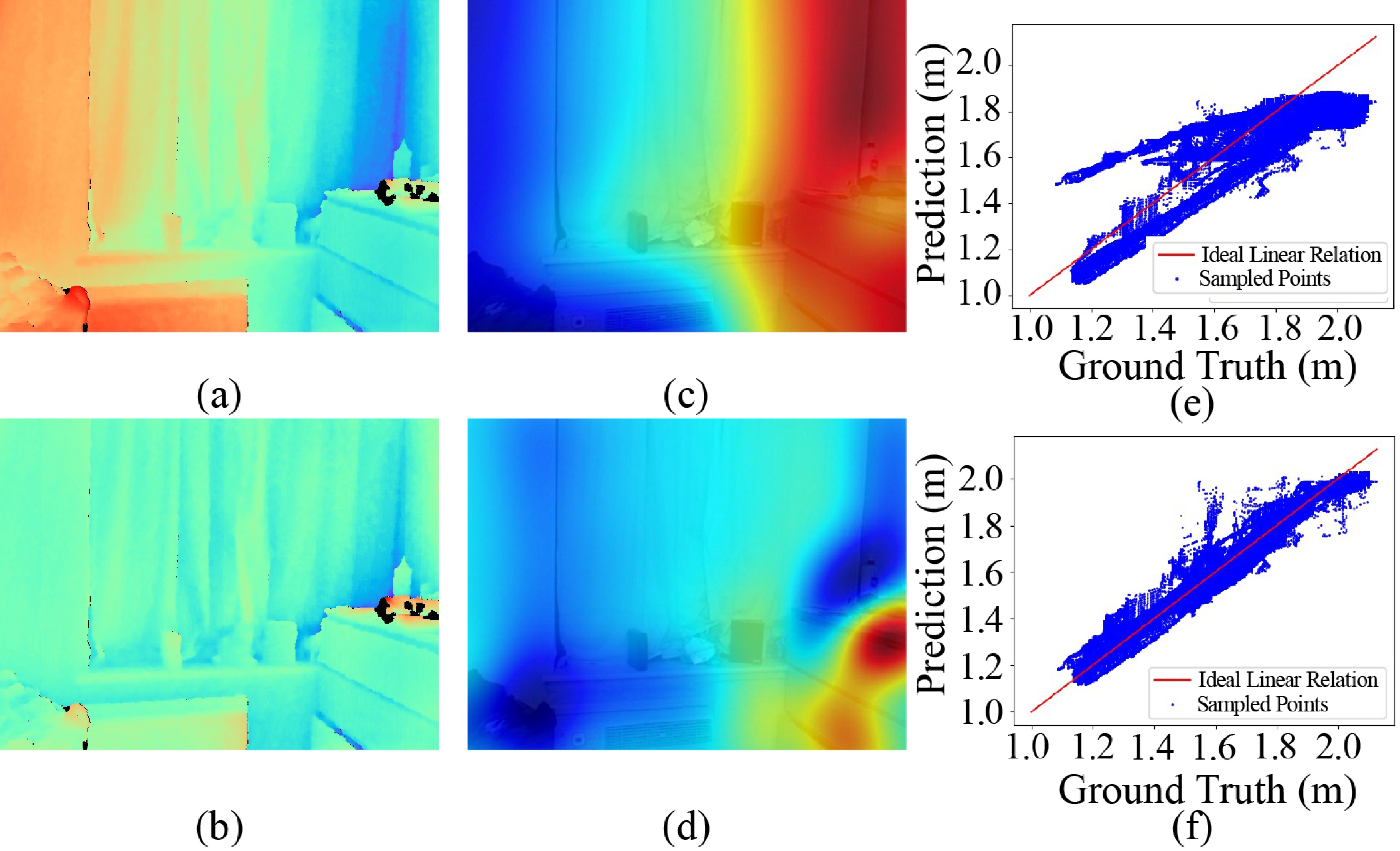
Figure 1. The per-pixel error maps of ground-truth depth and predicted depth aligned through (a) global recovery and (b) local recovery, respectively. (c) The scale map and (d) the shift map of local recovery. Distribution of prediction-GT pairs obtained via (e) global recovery and (f) local recovery individually.
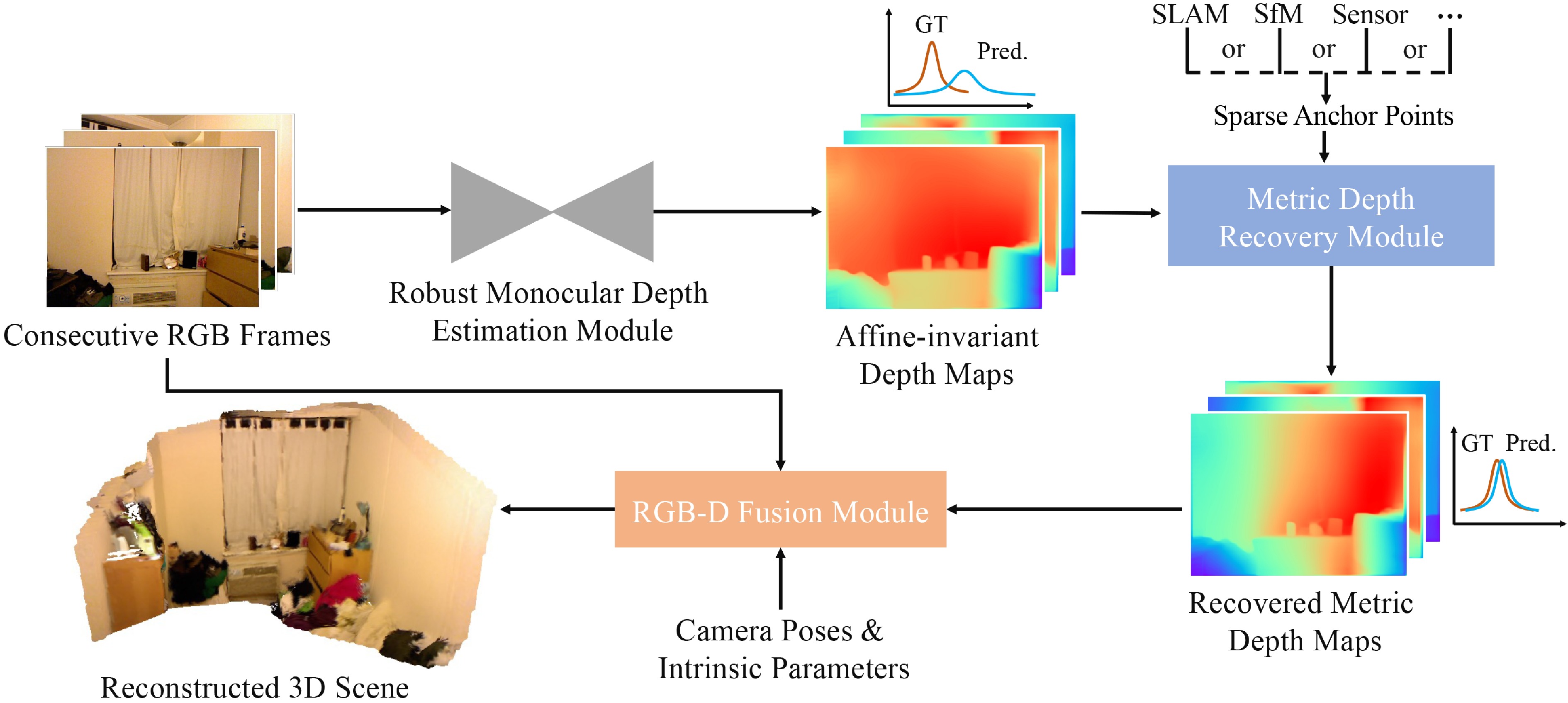
Figure 2. The pipeline for dense 3D scene reconstruction. The robust monocular depth estimation model trained on 6.3 million images, locally weighted linear regression strategy, and TSDF fusion[35] are the main components of our method.
| [1] |
Yin W, Zhang J, Wang O, et al. Learning to recover 3D scene shape from a single image. In: 2021 EEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, TN, USA: IEEE, 2021 : 204–213.
|
| [2] |
Ranftl R, Bochkovskiy A, Koltun V. Vision transformers for dense prediction. In: 2021 IEEE/CVF International Conference on Computer Vision (ICCV). Montreal, QC, Canada: IEEE, 2021 : 12159.
|
| [3] |
Ranftl R, Lasinger K, Hafner D, et al. Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44: 1623–1637. doi: 10.1109/tpami.2020.3019967
|
| [4] |
Xian K, Zhang J, Wang O, et al. Structure-guided ranking loss for single image depth prediction. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, WA, USA: IEEE, 2020 : 608–617.
|
| [5] |
Li Z, Snavely N. MegaDepth: Learning single-view depth prediction from Internet photos. In: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT, USA: IEEE, 2018 : 2041–2050.
|
| [6] |
Chen W, Qian S, Fan D, et al. OASIS: A large-scale dataset for single image 3D in the wild. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, WA, USA: IEEE, 2020 : 676–685.
|
| [7] |
Yin W, Liu Y, Shen C. Virtual normal: Enforcing geometric constraints for accurate and robust depth prediction. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44: 7282–7295. doi: 10.1109/tpami.2021.3097396
|
| [8] |
Chen W, Fu Z, Yang D, et al. Single-image depth perception in the wild. In: NIPS'16: Proceedings of the 30th International Conference on Neural Information Processing Systems. New York: ACM , 2016 : 730–738.
|
| [9] |
Bian J W, Zhan H, Wang N, et al. Unsupervised scale-consistent depth learning from video. International Journal of Computer Vision, 2021, 129 (9): 2548–2564. doi: 10.1007/s11263-021-01484-6
|
| [10] |
Wang Y, Chao W L, Garg D, et al. Pseudo-LiDAR from visual depth estimation: Bridging the gap in 3D object detection for autonomous driving. In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA, USA: IEEE, 2019 : 8437–8445.
|
| [11] |
Peng W, Pan H, Liu H, et al. IDA-3D: Instance-depth-aware 3D object detection from stereo vision for autonomous driving. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, WA, USA: IEEE, 2020 : 13012.
|
| [12] |
Huang J, Chen Z, Ceylan D, et al. 6-DOF VR videos with a single 360-camera. In: 2017 IEEE Virtual Reality (VR). Los Angeles, CA, USA: IEEE, 2017 : 37–44.
|
| [13] |
Valentin J, Kowdle A, Barron J T, et al. Depth from motion for smartphone AR. ACM Transactions on Graphics, 2018, 37 (6): 1–19. doi: 10.1145/3272127.3275041
|
| [14] |
Song S, Yu F, Zeng A, et al. Semantic scene completion from a single depth image. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, HI, USA: IEEE, 2017 : 1746–1754.
|
| [15] |
Silberman N, Hoiem D, Kohli P, et al. Indoor segmentation and support inference from RGBD images. In: Fitzgibbon A, Lazebnik S, Perona P, et al., editors. Computer Vision – ECCV 2012. Berlin: Springer, 2012 : 746–760.
|
| [16] |
Song S, Lichtenberg S P, Xiao J. SUN RGB-D: A RGB-D scene understanding benchmark suite. In: 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston, MA, USA: IEEE, 2015 : 567–576.
|
| [17] |
Yang X, Zhou L, Jiang H, et al. Mobile3DRecon: Real-time monocular 3D reconstruction on a mobile phone. IEEE Transactions on Visualization and Computer Graphics, 2020, 26 (12): 3446–3456. doi: 10.1109/tvcg.2020.3023634
|
| [18] |
Azinović D, Martin-Brualla R, Dan B Goldman D, B, et al. Neural RGB-D surface reconstruction. In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New Orleans, LA, USA: IEEE, 2022 : 6280–6291.
|
| [19] |
Eftekhar A, Sax A, Malik J, et al. Omnidata: A scalable pipeline for making multi-task mid-level vision datasets from 3D scans. In: 2021 IEEE/CVF International Conference on Computer Vision (ICCV). Montreal, QC, Canada: IEEE, 2021 : 10766–10776.
|
| [20] |
Bian J W, Zhan H, Wang N, et al. Auto-rectify network for unsupervised indoor depth estimation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44 (12): 9802–9813. doi: 10.1109/tpami.2021.3136220
|
| [21] |
Godard C, Mac Aodha O, Firman M, et al. Digging into self-supervised monocular depth estimation. In: 2019 IEEE/CVF International Conference on Computer Vision (ICCV). Seoul, Korea: IEEE, 2019 : 3827–3837.
|
| [22] |
Watson J, Mac Aodha O, Prisacariu V, et al. The temporal opportunist: Self-supervised multi-frame monocular depth. In: 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, TN, USA: IEEE, 2021 : 1164–1174.
|
| [23] |
Luo X, Huang J B, Szeliski R, et al. Consistent video depth estimation. ACM Transactions on Graphics, 2020, 39 (4): 71. doi: 10.1145/3386569.3392377
|
| [24] |
Kopf J, Rong X, Huang J B. Robust consistent video depth estimation. In: 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, TN, USA: IEEE, 2021 : 1611–1621.
|
| [25] |
Park J, Joo K, Hu Z, et al. Non-local spatial propagation network for depth completion. In: Vedaldi A, Bischof H, Brox T, et al., editors. Computer Vision – ECCV 2020. Cham: Springer, 2020 : 120–136.
|
| [26] |
Wong A, Soatto S. Unsupervised depth completion with calibrated backprojection layers. In: 2021 IEEE/CVF International Conference on Computer Vision (ICCV). Montreal, QC, Canada: IEEE, 2021 : 12727–12736.
|
| [27] |
Wong A, Cicek S, Soatto S. Learning topology from synthetic data for unsupervised depth completion. IEEE Robotics and Automation Letters, 2021, 6 (2): 1495–1502. doi: 10.1109/lra.2021.3058072
|
| [28] |
Yang Y, Wong A, Soatto S. Dense depth posterior (DDP) from single image and sparse range. In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA, USA: IEEE, 2019 : 3348–3357.
|
| [29] |
He K, Zhang X, Ren S, et al. Deep residual learning for image recognition. In: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, NV, USA: IEEE, 2016 : 770–778.
|
| [30] |
Liu Z, Lin Y, Cao Y, et al. Swin transformer: Hierarchical vision transformer using shifted windows. In: 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada: IEEE, 2021 : 9992–10002.
|
| [31] |
Schönberger J L, Frahm J M. Structure-from-motion revisited. In: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, NV, USA: IEEE, 2016 : 4104–4113.
|
| [32] |
Teed Z, Deng J. DeepV2D: Video to depth with differentiable structure from motion. arXiv: 1812.04605, 2018 .
|
| [33] |
Liu C, Gu J, Kim K, et al. Neural RGB@D sensing: Depth and uncertainty from a video camera. In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA: IEEE, 2019 : 10978–10987.
|
| [34] |
Düzçeker A, Galliani S, Vogel C, et al. DeepVideoMVS: Multi-view stereo on video with recurrent spatio-temporal fusion. In: 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, TN, USA: IEEE, 2021 : 15319–15328.
|
| [35] |
Zeng A, Song S, Nießner M, et al. 3DMatch: Learning local geometric descriptors from RGB-D reconstructions. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, HI, USA: IEEE, 2017 : 199–208.
|
| [36] |
Mur-Artal R, Montiel J M M, Tardós J D. ORB-SLAM: A versatile and accurate monocular SLAM system. IEEE Transactions on Robotics, 2015, 31: 1147–1163. doi: 10.1109/tro.2015.2463671
|
| [37] |
Schönberger J L, Zheng E, Frahm J M, et al. Pixelwise view selection for unstructured multi-view stereo. In: European conference on computer vision. Cham: Springer, 2016 : 501–518.
|
| [38] |
Im S, Jeon H G, Lin S, et al. DPSNet: End to-end deep plane sweep stereo. arXiv: 1905.00538, 2019 .
|
| [39] |
Wang C, Lucey S, Perazzi F, et al. Web stereo video supervision for depth prediction from dynamic scenes. In: 2019 International Conference on 3D Vision (3DV). Quebec City, QC, Canada: IEEE, 2019 : 348–357.
|
| [40] |
Chen W, Qian S, Deng J. Learning single-image depth from videos using quality assessment networks. In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA, USA: IEEE, 2019 : 5597–5606.
|
| [41] |
Xie S, Girshick R, Dollár P, et al. Aggregated residual transformations for deep neural networks. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, HI, USA: IEEE, 2017 : 5987–5995.
|
| [42] |
Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv: 2010.11929, 2021 .
|

ISSN 0253-2778
CN 34-1054/N
Copyright © Editorial Office of JUSTC, All Rights Reserved. 皖ICP备05002528号
Supported by:
Beijing Renhe Information Technology Co. Ltd





 DownLoad:
DownLoad: